雖然這篇精確度定義鄉民發文沒有被收入到精華區:在精確度定義這個話題中,我們另外找到其它相關的精選爆讚文章
在 精確度定義產品中有21篇Facebook貼文,粉絲數超過13萬的網紅蔡依橙的閱讀筆記,也在其Facebook貼文中提到, 💥 20 個 #常見的統計錯誤,你犯過,或是犯了卻不知道嗎?⠀ ⠀ MedCalc 的作者 Frank,在 Facebook 分享了一篇跟統計相關的文章,叫做「生物醫學研究文章中,連你都可以發現的 20 個統計錯誤」,很有意思。(連結請見原始貼文) ⠀ 我(蔡依橙)認真看完後,覺得蠻不錯的,於是把這...
同時也有3部Youtube影片,追蹤數超過4,400的網紅A-PEI阿佩,也在其Youtube影片中提到,洛麗塔及第套刷有優點有缺點,缺點太致命所以不是我的蜜糖。 詳細內容請點完整資訊看完噢! ============== 關於阿佩 BLOG:http://wupeiyu.pixnet.net/blog FB:https://www.facebook.com/wupeiyu123/ MAIL:wu...
精確度定義 在 生奧之路 Instagram 的最佳貼文
2021-07-11 08:51:36
#深奧廢文 3 為什麼要刷題? 許多人認為,題目練習越多越好 但,許多人忽略的真相是: 「刷題不是為了把題目寫完,而是為了要進步。」 若你盲目執著將習題都寫完,你將會浪費時間在無效(futile)的練習上。如果你經常覺得「努力和成果不成正比」,就意味著你目前的練習模式,對於達成目標還不夠充分。...
精確度定義 在 ?了概 - 5 分鐘看懂重要事件 Instagram 的精選貼文
2021-08-19 00:48:43
❓欸,到底是「零檢出」還是「未檢出」❓ 自從台灣宣布要開放含萊克多巴胺的美豬後,台灣的反對聲浪沸沸揚揚,而許多縣市都自行追求要「零檢出」。但什麼是「零檢出」呢? ⠀ 儘管沒有明確定義,但普遍認定「零檢出」就是濃度 0。但過去測不出來濃度,而顯示 0 的那些檢測,最終仍可能隨著檢驗設備的精確度不斷提...
-
精確度定義 在 A-PEI阿佩 Youtube 的最讚貼文
2017-10-27 12:39:18洛麗塔及第套刷有優點有缺點,缺點太致命所以不是我的蜜糖。
詳細內容請點完整資訊看完噢!
==============
關於阿佩
BLOG:http://wupeiyu.pixnet.net/blog
FB:https://www.facebook.com/wupeiyu123/
MAIL:wupeiyu123@yahoo.com.tw
============
本文是自購產品心得文,請勿任意轉載、商業使用。
============
洛麗塔及第套刷算是我在一兩個月前就買的刷具,
還記得當時一收到就很興奮得開心直播了呢!
但用過好一陣子之後,這套刷我就不想再多說什麼了,
因為對我而言不值得分享或推薦。
猶記得剛收到的時候摸那刷毛真是柔順舒服,
而且因為是提純細光峰羊毛的關係,
動物毛的抓粉力、釋粉力、暈染效果都不在話下,
剛收到這套刷具的時候我的確是喜歡的。
但問題出在我洗過洛麗塔及第套刷大約兩三次之後,
刷毛摸起來卻出現澀感,
不若一開始收到那麼細緻順滑,
甚至毛峰會有些微刺感了。
我跟其他同樣也買了洛麗塔及第套刷的朋友聊起,
她們洗刷後的感想跟我一樣,
毛質不如洗刷前的滑順,觸感也產生落差。
於是我又與一群研究刷毛很深入的朋友(其中也有刷具製造者)討論,
當中有一位朋友提到,她買了這套刷具回家摸過使用過發現,
她評估,洛麗塔及第這套刷具的刷毛應該是經過柔軟處理的,
(可能是浸泡柔軟劑或者其他)
因而導致刷具在剛收到摸的時候是非常柔滑,
但不耐洗,洗過幾次之後刷毛本質就有些原形畢露了。
再者是,洛麗塔及第這套刷具雖然強調用毛是提純細光峰,
但它的毛條細緻度、毛條的直曲等等毛條外觀,
著實不如我手邊的琴制或艾諾琪的細光峰或提純細光峰刷具,
我只能說也許洛莉塔的提純細光峰相較於其他刷廠,
可能在"提純"的定義上與其他刷廠有落差吧。
但如果洛麗塔的"提純細光峰"只能提到這樣的程度,
老實說我是有些失望的。
再來要提到的是洛麗塔及第套刷總共有14支,
包含6支臉部刷具以及7支眼部刷具還有1支唇刷。
臉部刷具的部分01蜜粉刷、02斜角修容刷是沒有太大問題的,
但是03粉餅刷過於鬆散難以增加粉餅的遮瑕力,
04重點腮紅刷又過於緊實容易刷出色塊腮紅,上粉餅又太小,
05斜角腮紅打亮刷堪用,但功能性單一,
06打亮刷刷型過於鬆散,打亮部位精確度不夠。
至於眼刷的部分則是細節處理刷具不足,
07大眼影刷可打底可化鼻影,但對部分人來說體積太大,
08眼影刷做為打底比較適合,
09壓色刷類似MAC239,刷型不錯適合壓色,
10馬尾暈染刷大小適中、刷型好,值得購入但要考慮洗後毛質,
11長毛眼影刷做為鋪色或暈染都可,值得購入但要考慮洗後毛質,
12圓頭鉛筆刷不夠細緻,可暈染上眼影但難以化下眼影或眼頭,
13小扁眼影刷算是整套刷具當中能處理眼妝細節的刷。
至於14號唇刷就是唇刷,要用來遮瑕或者上霜狀眼影也可以,
中規中矩。
然而,洛麗塔及第也是有優點的,
第一,就是便宜,14支刷具算下來只要台幣兩千多塊,
平均一枝刷只要一百多塊錢,便宜,C/P值高。
第二,有些刷型還是好用的,例如蜜粉刷、斜角刷、
大眼影刷、馬尾暈染刷、11號鋪色刷以及13號小扁眼影刷,
其實及第比較適合單買一些常用的刷型,不適合一次買整套。
基本上,如果及第可以改善毛質,
不要洗前洗後產生落差,還是可以的。
至於所謂的洗刷前洗刷後的落差,
如果要比喻,以剛收到那種柔軟滑順不刺為100分的話,
洗過幾次之後刷毛的毛質觸感大概會只剩下80-85分。
如果不是很介意這個缺點的朋友,
在預算上以及功能上是可以考慮購入,
但我個人對於洗前洗後刷毛落差覺得很感冒,
畢竟我的工作性質養成我的習慣就是經常性洗刷,
如果剛買的時候很棒棒洗完的時候很掉漆那我會很吐血。
所以是否購入洛麗塔及第這套刷具,就看個人考量了。
希望我的淘寶琴制刷具使用分享對有興趣的各位能有點參考性。:)
我最信任的刷具賣家 FB 「岑岑愛刷具」
======
相機:PANASONIC GF8
剪輯軟體:MOVIE MAKER![post-title]()
-
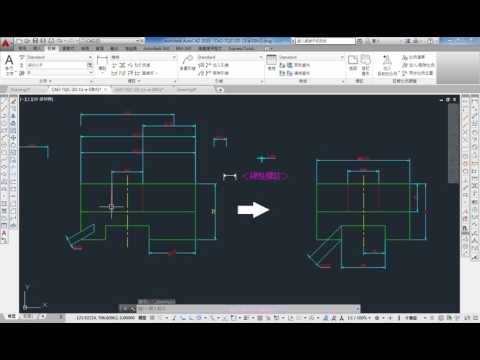
精確度定義 在 鍾日欣 Youtube 的最讚貼文
2016-08-16 18:40:50我是JC老師
電腦相關課程授課超過6000小時的一位AutoCAD課程講師
由於實在太多同學向JC老師反映,希望可以有線上課程學習,所以就決定錄製一系列的AutoCAD線上影片教學
而且不加密、不設限、不販售,就是純分享,希望可以幫助到有需要的朋友們
如果這部AutoCAD教學影片對你有幫助的話,請幫我按個讚,給我點鼓勵,也多分享給需要的朋友們喔~
---------------------------------------------------------------------------------------------------------
● 「主要單位」頁籤
◆ 設定主要標註單位的格式和精確度,以及設定標註文字的字首和字尾。
◆ 線性標註:設定線性標註的格式與精確度。
★ 單位格式:為除「角度」之外的所有標註類型設定目前單位格式。(DIMLUNIT 系統變數)。堆疊分數中數字的相對大小由系統變數 DIMTFAC 決定 (與公差值使用該系統變數的方式相同)。
★ 精確度:顯示與設定標註文字中的小數位數。(DIMDEC 系統變數)
★ 分數格式:設定分數的格式。(DIMFRAC 系統變數)
★ 小數分隔符號:設定十進位格式的分隔符號。(DIMDSEP 系統變數)
★ 捨入:除了「角度」之外,為所有標註類型的標註測量設定最接近捨入值。(系統變數 DIMRND)。如果輸入值 0.25,則會將所有距離捨入到最接近 0.25 個單位的值。如果輸入值 1.0,則會將所有標註距離捨入到最接近的整數。請注意,小數點後的位數取決於「精確度」設定。
★ 字首:在標註文字中指定的字首。(DIMPOST 系統變數)
★ 字尾:在標註文字中指定的字尾。(DIMPOST 系統變數)
◆ 度量比例:定義線性比例選項。主要套用到舊式圖面。
★ 比例係數:設定線性標註測量的比例係數。建議您不要變更預設值 1.00。(DIMLFAC 系統變數)。例如,如果輸入 2, 則 1 英吋的線會顯示為兩英吋。該值不套用到角度標註,也不套用到捨入值或正負公差值。
★ 僅套用到配置標註:僅將測量值比例係數套用到在配置視埠中建立的標註。該設定應該處於不勾選狀態,使用非關聯式標註的情況除外。(DIMLFAC 系統變數)
◆ 零抑制:控制前導零與結尾零、以及零英呎與零英吋的抑制。(DIMZIN 系統變數)
★ 前導:抑制所有十進位標註中的前導零。例如,0.5000 會變為 .5000。選取前導可使用次要單位顯示小於一個單位的標註距離。
★ 次要單位係數:設定某單位的次要單位數字。它用於在距離小於一個單位時使用次要單位計算標註距離。例如,如果在字尾為 m 時輸入 100,則次要單位字尾將以 cm 顯示。
★ 次要單位字尾:在標註值次要單位後包括字尾。您可以輸入文字或使用控制碼來顯示特殊符號。例如,輸入 cm 可讓 .96m 顯示為 96cm。
★ 結尾:抑制所有十進位標註的結尾零。例如,12.5000 變成 12.5,30.0000 變成 30。
★ 0 英呎:在距離小於 1 英呎時抑制英呎與英吋標註的英呎部分。例如,0'-6 1/2" 變成 6 1/2"。
★ 0 英吋:在距離是整數英呎時抑制英呎與英吋標註的英吋部分。例如,1'-0" 變成 1'。
◆ 角度標註:顯示與設定角度標註的目前角度格式。
★ 單位格式:設定角度單位格式。(DIMAUNIT 系統變數)
★ 精確度:設定角度標註的小數位數。(系統變數 DIMADEC)
★ 零抑制:控制前導零和結尾零的抑制。(DIMAZIN 系統變數)
▲ 前導:抑制角度十進位標註中的前導零。例如,0.5000 變成 .5000。
▲ 結尾:抑制角度十進位標註中的結尾零。例如,12.5000 變成 12.5,30.0000 變成 30。
● 「對照單位」頁籤
◆ 指定標註測量結果中對照單位的顯示,並設定對照單位的格式與精確度。
◆ 顯示對照單位:將替用測量單位加入到標註文字中。將系統變數 DIMALT 設定為 1。
◆ 對照單位乘法器:指定用作主要單位和對照單位之間的轉換係數的乘法器。例如,若要將英吋轉換為公釐,則輸入 25.4。此值不會影響角度標註,而且不會套用到捨入值或正負公差值。(系統變數 DIMALTF)
◆ 距離捨入至:除了「角度」之外,設定所有標註類型的對照單位捨入規則。如果輸入值 0.25,則所有的對照單位都被捨入到最接近 0.25 個單位的數值。如果輸入值 1.0,則所有標註測量值會被捨入到最接近的整數。小數點後的位數取決於「精確度」設定。(系統變數 DIMALTRND)
---------------------------------------------------------------------------------------------------------
AutoCAD線上影片教學範例下載:https://goo.gl/DhVTau
AutoCAD2D常用快速鍵清單整理:http://goo.gl/SjNIxz
AutoCAD2015線上影片教學頻道:https://goo.gl/Q5aCf5
JC老師個人網站:http://jc-d.net/
JC老師個人FB:https://www.facebook.com/ericjc.tw![post-title]()
-
精確度定義 在 TechaLook 中文台 Youtube 的最佳解答
2013-05-31 16:59:15經由 Tech a Look 介紹體驗 Genius ECO 系列中最環保的無線滑鼠,型號為 NX-ECO。
Genius NX-ECO 環保筆電滑鼠為「不含電池」一詞賦予了全新定義並擁有業界最先進的免電池設計,所 以使用時再也不需要電池。只要將 Micro USB 充電式連接線插入電腦的 USB,無線 BlueEye 滑鼠在短短三分鐘內即可充電完畢! 此外,內建的超電容創新設計也可讓 NX-ECO 無線滑鼠充電將近 100,000 次。
在 Genius BlueEye 技術與 2.4Ghz 雙向技術搭配之下,您幾乎能夠隨處使用滑鼠,且在長達 15 公尺的距離內絕不遭受任何干擾。NX-ECO 的 dpi 按鍵可讓您方便控管滑鼠,使 dpi 在 800 到 1600 之間切換,自行調整滑鼠的速度或精確度。此外,滑鼠內部的接收器與 USB 連接線收納槽可為您免去物品亂放而找不到的窘境,出門在外時,此貼心設計立刻派上用場。
以上產品資料參考Genius官方網站 http://www.geniusnet.com.tw/
想知道更多關於3C資訊詳細內容請持續鎖定 Tech a Look
網址 : http://www.techalook.com.tw/
Facebook : http://www.facebook.com/techalook.com.tw![post-title]()





精確度定義 在 蔡依橙的閱讀筆記 Facebook 的最佳貼文
💥 20 個 #常見的統計錯誤,你犯過,或是犯了卻不知道嗎?⠀
⠀
MedCalc 的作者 Frank,在 Facebook 分享了一篇跟統計相關的文章,叫做「生物醫學研究文章中,連你都可以發現的 20 個統計錯誤」,很有意思。(連結請見原始貼文)
⠀
我(蔡依橙)認真看完後,覺得蠻不錯的,於是把這 20 個統計錯誤的標題翻成中文,協助大家節省時間,如果剛好有興趣的,可再針對該部分去閱讀原文。接著,分享一些我看完之後的想法。
⠀
⠀
1. 數值報告時,提供了不必要的精確。例如 60 公斤體重,硬要寫成 60.18 公斤。
⠀
2. 將連續變項分組,變成次序變項,但沒有說明為什麼這樣分。像是 CRP 不以數值去統計,而分成低、中、高三組,卻沒說明為什麼這樣分。
⠀
3. 配對資料,只報告各組平均,卻沒報告其改變。也就是只報告治療前血壓、治療後血壓,卻沒報告有多少人上升、多少人下降、平均下降多少。
⠀
4. 描述性統計的誤用,尤其該用 median (interquartile range) 的,硬是用成 mean +- SD。
⠀
5. 使用 standard error of the mean (SEM) 描述量測的精確度,而非 95% CI。
⠀
6. 只報告 p 值,卻沒提到差值以及臨床意義。
⠀
7. 誤用統計方式。尤其常見的是混淆有母數跟無母數統計方法。
⠀
8. 使用線性迴歸,卻沒有先確定資料之間是真的有線性關係。
⠀
9. 沒有使用全部的資料,然後又沒把去掉的資料「為什麼被去掉」說清楚。
⠀
10. 多組比較的 p 值校正問題。
⠀
11. 在隨機分組研究時,過於詳盡地比較了兩組受試者的基本資料,像是性別比例、年齡、體重、血壓等等,而且資料好得太奇怪。
⠀
12. 報告檢驗數值時,沒有定義 normal 與 abnormal。
⠀
13. 計算 sensitivity 與 specificity 時,沒有說明一些介在灰色地帶的檢查結果,如何呈現與去除。
⠀
14. 使用圖片與表格,只是為了儲存數據,而非以協助讀者理解為出發點。
⠀
15. 畫出來的數據圖,視覺主觀上給人的印象,竟然跟數據本身不同。
⠀
16. 在報告數據與解讀時,搞不清楚 units of observation 是什麼,例如心臟病的觀察研究,在 1000 個患者中有 18 位心臟病發,那 units of observation 就是 18。但如果這個研究是以診斷正確率為主,那 sample size 就是 1000。
⠀
17. 把不顯著的統計,或 low power,解讀成 negative,而非 inconclusive。
⠀
18. 分不清楚解釋性研究與實務性研究,前者為 explanatory / efficacy / laboratory,後者為 pragmatic / effectiveness / real world。嘗試兩種混著做,結果兩邊都做不好。
⠀
19. 沒有用臨床能理解的方式來報告最終結果。
⠀
20. 把統計的顯著性,當成臨床的重要性。例如:癌症用新藥治療,統計上很顯著的好,但追蹤了五年,患者只延長了七天的壽命。這就是統計有顯著,但臨床意義不大的例子。
⠀
⠀
🗨 我(蔡依橙)的一些想法
⠀
由統計專業人的角度,來看生物醫學發表,是很有警惕意義的,能讓準備發表的朋友,仔細看看自己是不是也犯了相關的錯誤。
⠀
但另一個角度看,作者也提到,這些錯誤在幾乎一半的生物醫學論文上反覆出現!這就代表,其實生物醫學論文要刊登,並不代表我們什麼錯都不能犯,相反地,這 20 個錯誤裡頭,有些就算犯了,也還是能被刊登。
⠀
以我們自己發表,以及過去協助同學的經驗來說,我會認為 2、7、10、14、15,是初學者也 #必須理解並避開的,其他的則是發表起步了之後,陸陸續續去注意,在往更高分期刊挑戰時,逐漸進步就行。
⠀
實務上,3 分以下的醫學期刊,幾乎沒有專門的統計查核,你只要能通過「一般同行」的統計知識審查就行。也就是說,我是一個放射科醫師,剛開始起步,投稿到放射科 3 分以下期刊,文章中的統計,只要「#一般有在做研究的放射科醫師」覺得可以就行,不見得要到「統計專家看過並挑不出毛病」。
⠀
對於初學者如何起步,實務的協助,新思惟規劃了各種類型的研究課程,歡迎有興趣的朋友可以參考。目前正在開放報名中的,有以下三場工作坊,歡迎您瞭解各課程的課綱後,評估挑選最符合您需求的內容,前來上課,讓我們協助您成功起步。
⠀
🟠 2021 / 11 / 7(日)統合分析工作坊
無經費、資源少也能發表,不用 IRB 且免收案的好選擇。
https://meta-analysis.innovarad.tw/event/
⠀
🔵 2021 / 10 / 17(日)臨床研究與發表工作坊
全新改款!跟著國際學者走,讓你寫作投稿都上手。
https://clip2014.innovarad.tw/event/
⠀
🟢 2021 / 10 / 16(六)個案報告、技術發表與文獻回顧工作坊
把臨床上的各種想法,在 PubMed 化作專業生涯上的里程碑。
https://casereport.innovarad.tw/event/
⠀ ⠀
不只是說說而已,我們會舉實例,說明其意義、如何避開,在互動實作過程,實際由各位在自己的電腦上操作,從數據到軟體,從統計到繪圖,一次搞定,並避開常見錯誤,是真正以 #初學者起步 為核心的規劃。
⠀
⠀
二十個常見的統計錯誤,與實務寫作時的考量。
🔗 原始貼文 │ https://bit.ly/2WESphu
精確度定義 在 新思惟國際 Facebook 的最佳貼文
💥 20 個 #常見的統計錯誤,你犯過,或是犯了卻不知道嗎?⠀
⠀
MedCalc 的作者 Frank,在 Facebook 分享了一篇跟統計相關的文章,叫做「生物醫學研究文章中,連你都可以發現的 20 個統計錯誤」,很有意思。(連結請見原始貼文)
⠀
我(蔡依橙)認真看完後,覺得蠻不錯的,於是把這 20 個統計錯誤的標題翻成中文,協助大家節省時間,如果剛好有興趣的,可再針對該部分去閱讀原文。接著,分享一些我看完之後的想法。
⠀
⠀
1. 數值報告時,提供了不必要的精確。例如 60 公斤體重,硬要寫成 60.18 公斤。
⠀
2. 將連續變項分組,變成次序變項,但沒有說明為什麼這樣分。像是 CRP 不以數值去統計,而分成低、中、高三組,卻沒說明為什麼這樣分。
⠀
3. 配對資料,只報告各組平均,卻沒報告其改變。也就是只報告治療前血壓、治療後血壓,卻沒報告有多少人上升、多少人下降、平均下降多少。
⠀
4. 描述性統計的誤用,尤其該用 median (interquartile range) 的,硬是用成 mean +- SD。
⠀
5. 使用 standard error of the mean (SEM) 描述量測的精確度,而非 95% CI。
⠀
6. 只報告 p 值,卻沒提到差值以及臨床意義。
⠀
7. 誤用統計方式。尤其常見的是混淆有母數跟無母數統計方法。
⠀
8. 使用線性迴歸,卻沒有先確定資料之間是真的有線性關係。
⠀
9. 沒有使用全部的資料,然後又沒把去掉的資料「為什麼被去掉」說清楚。
⠀
10. 多組比較的 p 值校正問題。
⠀
11. 在隨機分組研究時,過於詳盡地比較了兩組受試者的基本資料,像是性別比例、年齡、體重、血壓等等,而且資料好得太奇怪。
⠀
12. 報告檢驗數值時,沒有定義 normal 與 abnormal。
⠀
13. 計算 sensitivity 與 specificity 時,沒有說明一些介在灰色地帶的檢查結果,如何呈現與去除。
⠀
14. 使用圖片與表格,只是為了儲存數據,而非以協助讀者理解為出發點。
⠀
15. 畫出來的數據圖,視覺主觀上給人的印象,竟然跟數據本身不同。
⠀
16. 在報告數據與解讀時,搞不清楚 units of observation 是什麼,例如心臟病的觀察研究,在 1000 個患者中有 18 位心臟病發,那 units of observation 就是 18。但如果這個研究是以診斷正確率為主,那 sample size 就是 1000。
⠀
17. 把不顯著的統計,或 low power,解讀成 negative,而非 inconclusive。
⠀
18. 分不清楚解釋性研究與實務性研究,前者為 explanatory / efficacy / laboratory,後者為 pragmatic / effectiveness / real world。嘗試兩種混著做,結果兩邊都做不好。
⠀
19. 沒有用臨床能理解的方式來報告最終結果。
⠀
20. 把統計的顯著性,當成臨床的重要性。例如:癌症用新藥治療,統計上很顯著的好,但追蹤了五年,患者只延長了七天的壽命。這就是統計有顯著,但臨床意義不大的例子。
⠀
⠀
🗨 我(蔡依橙)的一些想法
⠀
由統計專業人的角度,來看生物醫學發表,是很有警惕意義的,能讓準備發表的朋友,仔細看看自己是不是也犯了相關的錯誤。
⠀
但另一個角度看,作者也提到,這些錯誤在幾乎一半的生物醫學論文上反覆出現!這就代表,其實生物醫學論文要刊登,並不代表我們什麼錯都不能犯,相反地,這 20 個錯誤裡頭,有些就算犯了,也還是能被刊登。
⠀
以我們自己發表,以及過去協助同學的經驗來說,我會認為 2、7、10、14、15,是初學者也 #必須理解並避開的,其他的則是發表起步了之後,陸陸續續去注意,在往更高分期刊挑戰時,逐漸進步就行。
⠀
實務上,3 分以下的醫學期刊,幾乎沒有專門的統計查核,你只要能通過「一般同行」的統計知識審查就行。也就是說,我是一個放射科醫師,剛開始起步,投稿到放射科 3 分以下期刊,文章中的統計,只要「#一般有在做研究的放射科醫師」覺得可以就行,不見得要到「統計專家看過並挑不出毛病」。
⠀
對於初學者如何起步,實務的協助,新思惟規劃了各種類型的研究課程,歡迎有興趣的朋友可以參考。目前正在開放報名中的,有以下三場工作坊,歡迎您瞭解各課程的課綱後,評估挑選最符合您需求的內容,前來上課,讓我們協助您成功起步。
⠀
🟠 2021 / 11 / 7(日)統合分析工作坊
無經費、資源少也能發表,不用 IRB 且免收案的好選擇。
https://meta-analysis.innovarad.tw/event/
⠀
🔵 2021 / 10 / 17(日)臨床研究與發表工作坊
全新改款!跟著國際學者走,讓你寫作投稿都上手。
https://clip2014.innovarad.tw/event/
⠀
🟢 2021 / 10 / 16(六)個案報告、技術發表與文獻回顧工作坊
把臨床上的各種想法,在 PubMed 化作專業生涯上的里程碑。
https://casereport.innovarad.tw/event/
⠀ ⠀
不只是說說而已,我們會舉實例,說明其意義、如何避開,在互動實作過程,實際由各位在自己的電腦上操作,從數據到軟體,從統計到繪圖,一次搞定,並避開常見錯誤,是真正以 #初學者起步 為核心的規劃。
⠀
⠀
二十個常見的統計錯誤,與實務寫作時的考量。
🔗 原始貼文 │ https://bit.ly/2WESphu
精確度定義 在 台灣物聯網實驗室 IOT Labs Facebook 的最讚貼文
摩爾定律放緩 靠啥提升AI晶片運算力?
作者 : 黃燁鋒,EE Times China
2021-07-26
對於電子科技革命的即將終結的說法,一般認為即是指摩爾定律的終結——摩爾定律一旦無法延續,也就意味著資訊技術的整棟大樓建造都將出現停滯,那麼第三次科技革命也就正式結束了。這種聲音似乎是從十多年前就有的,但這波革命始終也沒有結束。AI技術本質上仍然是第三次科技革命的延續……
人工智慧(AI)的技術發展,被很多人形容為第四次科技革命。前三次科技革命,分別是蒸汽、電氣、資訊技術(電子科技)革命。彷彿這“第四次”有很多種說辭,比如有人說第四次科技革命是生物技術革命,還有人說是量子技術革命。但既然AI也是第四次科技革命之一的候選技術,而且作為資訊技術的組成部分,卻又獨立於資訊技術,即表示它有獨到之處。
電子科技革命的即將終結,一般認為即是指摩爾定律的終結——摩爾定律一旦無法延續,也就意味著資訊技術的整棟大樓建造都將出現停滯,那麼第三次科技革命也就正式結束了。這種聲音似乎是從十多年前就有,但這波革命始終也沒有結束。
AI技術本質上仍然是第三次科技革命的延續,它的發展也依託於幾十年來半導體科技的進步。這些年出現了不少專門的AI晶片——而且市場參與者相眾多。當某一個類別的技術發展到出現一種專門的處理器為之服務的程度,那麼這個領域自然就不可小覷,就像當年GPU出現專門為圖形運算服務一樣。
所以AI晶片被形容為CPU、GPU之後的第三大類電腦處理器。AI專用處理器的出現,很大程度上也是因為摩爾定律的發展進入緩慢期:電晶體的尺寸縮減速度,已經無法滿足需求,所以就必須有某種專用架構(DSA)出現,以快速提升晶片效率,也才有了專門的AI晶片。
另一方面,摩爾定律的延緩也成為AI晶片發展的桎梏。在摩爾定律和登納德縮放比例定律(Dennard Scaling)發展的前期,電晶體製程進步為晶片帶來了相當大的助益,那是「happy scaling down」的時代——CPU、GPU都是這個時代受益,不過Dennard Scaling早在45nm時期就失效了。
AI晶片作為第三大類處理器,在這波發展中沒有趕上happy scaling down的好時機。與此同時,AI應用對運算力的需求越來越貪婪。今年WAIC晶片論壇圓桌討論環節,燧原科技創始人暨CEO趙立東說:「現在訓練的GPT-3模型有1750億參數,接近人腦神經元數量,我以為這是最大的模型了,要千張Nvidia的GPU卡才能做。談到AI運算力需求、模型大小的問題,說最大模型超過萬億參數,又是10倍。」
英特爾(Intel)研究院副總裁、中國研究院院長宋繼強說:「前兩年用GPU訓練一個大規模的深度學習模型,其碳排放量相當於5台美式車整個生命週期產生的碳排量。」這也說明了AI運算力需求的貪婪,以及提供運算力的AI晶片不夠高效。
不過作為產業的底層驅動力,半導體製造技術仍源源不斷地為AI發展提供推力。本文將討論WAIC晶片論壇上聽到,針對這個問題的一些前瞻性解決方案——有些已經實現,有些則可能有待時代驗證。
XPU、摩爾定律和異質整合
「電腦產業中的貝爾定律,是說能效每提高1,000倍,就會衍生出一種新的運算形態。」中科院院士劉明在論壇上說,「若每瓦功耗只能支撐1KOPS的運算,當時的這種運算形態是超算;到了智慧型手機時代,能效就提高到每瓦1TOPS;未來的智慧終端我們要達到每瓦1POPS。 這對IC提出了非常高的要求,如果依然沿著CMOS這條路去走,當然可以,但會比較艱辛。」
針對性能和效率提升,除了尺寸微縮,半導體產業比較常見的思路是電晶體結構、晶片結構、材料等方面的最佳化,以及處理架構的革新。
(1)AI晶片本身其實就是對處理器架構的革新,從運算架構的層面來看,針對不同的應用方向造不同架構的處理器是常規,更專用的處理器能促成效率和性能的成倍增長,而不需要依賴於電晶體尺寸的微縮。比如GPU、神經網路處理器(NPU,即AI處理器),乃至更專用的ASIC出現,都是這類思路。
CPU、GPU、NPU、FPGA等不同類型的晶片各司其職,Intel這兩年一直在推行所謂的「XPU」策略就是用不同類型的處理器去做不同的事情,「整合起來各取所需,用組合拳會好過用一種武器去解決所有問題。」宋繼強說。Intel的晶片產品就涵蓋了幾個大類,Core CPU、Xe GPU,以及透過收購獲得的AI晶片Habana等。
另外針對不同類型的晶片,可能還有更具體的最佳化方案。如當代CPU普遍加入AVX512指令,本質上是特別針對深度學習做加強。「專用」的不一定是處理器,也可以是處理器內的某些特定單元,甚至固定功能單元,就好像GPU中加入專用的光線追蹤單元一樣,這是當代處理器普遍都在做的一件事。
(2)從電晶體、晶片結構層面來看,電晶體的尺寸現在仍然在縮減過程中,只不過縮減幅度相比過去變小了——而且為緩解電晶體性能的下降,需要有各種不同的技術來輔助尺寸變小。比如說在22nm節點之後,電晶體變為FinFET結構,在3nm之後,電晶體即將演變為Gate All Around FET結構。最終會演化為互補FET (CFET),其本質都是電晶體本身充分利用Z軸,來實現微縮性能的提升。
劉明認為,「除了基礎元件的變革,IC現在的發展還是比較多元化,包括新材料的引進、元件結構革新,也包括微影技術。長期賴以微縮的基本手段,現在也在發生巨大的變化,特別是未來3D的異質整合。這些多元技術的協同發展,都為晶片整體性能提升帶來了很好的增益。」
他並指出,「從電晶體級、到晶圓級,再到晶片堆疊、引線接合(lead bonding),精準度從毫米向奈米演進,互連密度大大提升。」從晶圓/裸晶的層面來看,則是眾所周知的朝more than moore’s law這樣的路線發展,比如把兩片裸晶疊起來。現在很熱門的chiplet技術就是比較典型的並不依賴於傳統電晶體尺寸微縮,來彈性擴展性能的方案。
台積電和Intel這兩年都在大推將不同類型的裸晶,異質整合的技術。2.5D封裝方案典型如台積電的CoWoS,Intel的EMIB,而在3D堆疊上,Intel的Core LakeField晶片就是用3D Foveros方案,將不同的裸晶疊在一起,甚至可以實現兩片運算裸晶的堆疊、互連。
之前的文章也提到過AMD剛發佈的3D V-Cache,將CPU的L3 cache裸晶疊在運算裸晶上方,將處理器的L3 cache大小增大至192MB,對儲存敏感延遲應用的性能提升。相比Intel,台積電這項技術的獨特之處在於裸晶間是以混合接合(hybrid bonding)的方式互連,而不是micro-bump,做到更小的打線間距,以及晶片之間數十倍通訊性能和效率提升。
這些方案也不直接依賴傳統的電晶體微縮方案。這裡實際上還有一個方面,即新材料的導入專家們沒有在論壇上多說,本文也略過不談。
1,000倍的性能提升
劉明談到,當電晶體微縮的空間沒有那麼大的時候,產業界傾向於採用新的策略來評價技術——「PPACt」——即Powe r(功耗)、Performance (性能)、Cost/Area-Time (成本/面積-時間)。t指的具體是time-to-market,理論上應該也屬於成本的一部分。
電晶體微縮方案失效以後,「多元化的技術變革,依然會讓IC性能得到進一步的提升。」劉明說,「根據預測,這些技術即使不再做尺寸微縮,也會讓IC的晶片性能做到500~1,000倍的提升,到2035年實現Zetta Flops的系統性能水準。且超算的發展還可以一如既往地前進;單裸晶儲存容量變得越來越大,IC依然會為產業發展提供基礎。」
500~1,000倍的預測來自DARPA,感覺有些過於樂觀。因為其中的不少技術存在比較大的邊際遞減效應,而且有更實際的工程問題待解決,比如運算裸晶疊層的散熱問題——即便業界對於這類工程問題的探討也始終在持續。
不過1,000倍的性能提升,的確說明摩爾定律的終結並不能代表第三次科技革命的終結,而且還有相當大的發展空間。尤其本文談的主要是AI晶片,而不是更具通用性的CPU。
矽光、記憶體內運算和神經型態運算
在非傳統發展路線上(以上內容都屬於半導體製造的常規思路),WAIC晶片論壇上宋繼強和劉明都提到了一些頗具代表性的技術方向(雖然這可能與他們自己的業務方向或研究方向有很大的關係)。這些技術可能尚未大規模推廣,或者仍在商業化的極早期。
(1)近記憶體運算和記憶體內運算:處理器性能和效率如今面臨的瓶頸,很大程度並不在單純的運算階段,而在資料傳輸和儲存方面——這也是共識。所以提升資料的傳輸和存取效率,可能是提升整體系統性能時,一個非常靠譜的思路。
這兩年市場上的處理器產品用「近記憶體運算」(near-memory computing)思路的,應該不在少數。所謂的近記憶體運算,就是讓儲存(如cache、memory)單元更靠近運算單元。CPU的多層cache結構(L1、L2、L3),以及電腦處理器cache、記憶體、硬碟這種多層儲存結構是常規。而「近記憶體運算」主要在於究竟有多「近」,cache記憶體有利於隱藏當代電腦架構中延遲和頻寬的局限性。
這兩年在近記憶體運算方面比較有代表性的,一是AMD——比如前文提到3D V-cache增大處理器的cache容量,還有其GPU不僅在裸晶內導入了Infinity Cache這種類似L3 cache的結構,也更早應用了HBM2記憶體方案。這些實踐都表明,儲存方面的革新的確能帶來性能的提升。
另外一個例子則是Graphcore的IPU處理器:IPU的特點之一是在裸晶內堆了相當多的cache資源,cache容量遠大於一般的GPU和AI晶片——也就避免了頻繁的訪問外部儲存資源的操作,極大提升頻寬、降低延遲和功耗。
近記憶體運算的本質仍然是馮紐曼架構(Von Neumann architecture)的延續。「在做處理的過程中,多層級的儲存結構,資料的搬運不僅僅在處理和儲存之間,還在不同的儲存層級之間。這樣頻繁的資料搬運帶來了頻寬延遲、功耗的問題。也就有了我們經常說的運算體系內的儲存牆的問題。」劉明說。
構建非馮(non-von Neumann)架構,把傳統的、以運算為中心的馮氏架構,變換一種新的運算範式。把部分運算力下推到儲存。這便是記憶體內運算(in-memory computing)的概念。
記憶體內運算的就現在看來還是比較新,也有稱其為「存算一體」。通常理解為在記憶體中嵌入演算法,儲存單元本身就有運算能力,理論上消除資料存取的延遲和功耗。記憶體內運算這個概念似乎這在資料爆炸時代格外醒目,畢竟可極大減少海量資料的移動操作。
其實記憶體內運算的概念都還沒有非常明確的定義。現階段它可能的內涵至少涉及到在儲記憶體內部,部分執行資料處理工作;主要應用於神經網路(因為非常契合神經網路的工作方式),以及這類晶片具體的工作方法上,可能更傾向於神經型態運算(neuromorphic computing)。
對於AI晶片而言,記憶體內運算的確是很好的思路。一般的GPU和AI晶片執行AI負載時,有比較頻繁的資料存取操作,這對性能和功耗都有影響。不過記憶體內運算的具體實施方案,在市場上也是五花八門,早期比較具有代表性的Mythic導入了一種矩陣乘的儲存架構,用40nm嵌入式NOR,在儲記憶體內部執行運算,不過替換掉了數位週邊電路,改用類比的方式。在陣列內部進行模擬運算。這家公司之前得到過美國國防部的資金支援。
劉明列舉了近記憶體運算和記憶體內運算兩種方案的例子。其中,近記憶體運算的這個方案應該和AMD的3D V-cache比較類似,把儲存裸晶和運算裸晶疊起來。
劉明指出,「這是我們最近的一個工作,採用hybrid bonding的技術,與矽通孔(TSV)做比較,hybrid bonding功耗是0.8pJ/bit,而TSV是4pJ/bit。延遲方面,hybrid bonding只有0.5ns,而TSV方案是3ns。」台積電在3D堆疊方面的領先優勢其實也體現在hybrid bonding混合鍵合上,前文也提到了它具備更高的互連密度和效率。
另外這套方案還將DRAM刷新頻率提高了一倍,從64ms提高至128ms,以降低功耗。「應對刷新率變慢出現拖尾bit,我們引入RRAM TCAM索引這些tail bits」劉明說。
記憶體內運算方面,「傳統運算是用布林邏輯,一個4位元的乘法需要用到幾百個電晶體,這個過程中需要進行資料來回的移動。記憶體內運算是利用單一元件的歐姆定律來完成一次乘法,然後利用基爾霍夫定律完成列的累加。」劉明表示,「這對於今天深度學習的矩陣乘非常有利。它是原位的運算和儲存,沒有資料搬運。」這是記憶體內運算的常規思路。
「無論是基於SRAM,還是基於新型記憶體,相比近記憶體運算都有明顯優勢,」劉明認為。下圖是記憶體內運算和近記憶體運算,精準度、能效等方面的對比,記憶體內運算架構對於低精準度運算有價值。
下圖則總結了業內主要的一些記憶體內運算研究,在精確度和能效方面的對應關係。劉明表示,「需要高精確度、高運算力的情況下,近記憶體運算目前還是有優勢。不過記憶體內運算是更新的技術,這幾年的進步也非常快。」
去年阿里達摩院發佈2020年十大科技趨勢中,有一個就是存算一體突破AI算力瓶頸。不過記憶體內運算面臨的商用挑戰也一點都不小。記憶體內運算的通常思路都是類比電路的運算方式,這對記憶體、運算單元設計都需要做工程上的考量。與此同時這樣的晶片究竟由誰來造也是個問題:是記憶體廠商,還是數文書處理器廠商?(三星推過記憶體內運算晶片,三星、Intel垂直整合型企業似乎很適合做記憶體內運算…)
(2)神經型態運算:神經型態運算和記憶體內運算一樣,也是新興技術的熱門話題,這項技術有時也叫作compute in memory,可以認為它是記憶體內運算的某種發展方向。神經型態和一般神經網路AI晶片的差異是,這種結構更偏「類人腦」。
進行神經型態研究的企業現在也逐漸變得多起來,劉明也提到了AI晶片「最終的理想是在結構層次模仿腦,元件層次逼近腦,功能層次超越人腦」的「類腦運算」。Intel是比較早關注神經型態運算研究的企業之一。
傳說中的Intel Loihi就是比較典型存算一體的架構,「這片裸晶裡面包含128個小核心,每個核心用於模擬1,024個神經元的運算結構。」宋繼強說,「這樣一塊晶片大概可以類比13萬個神經元。我們做到的是把768個晶片再連起來,構成接近1億神經元的系統,讓學術界的夥伴去試用。」
「它和深度學習加速器相比,沒有任何浮點運算——就像人腦裡面沒有乘加器。所以其學習和訓練方法是採用一種名為spike neutral network的路線,功耗很低,也可以訓練出做視覺辨識、語言辨識和其他種類的模型。」宋繼強認為,不採用同步時脈,「刺激的時候就是一個非同步電動勢,只有工作部分耗電,功耗是現在深度學習加速晶片的千分之一。」
「而且未來我們可以對不同區域做劃分,比如這兒是視覺區、那兒是語言區、那兒是觸覺區,同時進行多模態訓練,互相之間產生關聯。這是現在的深度學習模型無法比擬的。」宋繼強說。這種神經型態運算晶片,似乎也是Intel在XPU方向上探索不同架構運算的方向之一。
(2)微型化矽光:這個技術方向可能在層級上更偏高了一些,不再晶片架構層級,不過仍然值得一提。去年Intel在Labs Day上特別談到了自己在矽光(Silicon Photonics)的一些技術進展。其實矽光技術在連接資料中心的交換機方面,已有應用了,發出資料時,連接埠處會有個收發器把電訊號轉為光訊號,透過光纖來傳輸資料,另一端光訊號再轉為電訊號。不過傳統的光收發器成本都比較高,內部元件數量大,尺寸也就比較大。
Intel在整合化的矽光(IIIV族monolithic的光學整合化方案)方面應該是商業化走在比較前列的,就是把光和電子相關的組成部分高度整合到晶片上,用IC製造技術。未來的光通訊不只是資料中心機架到機架之間,也可以下沉到板級——就跟現在傳統的電I/O一樣。電互連的主要問題是功耗太大,也就是所謂的I/O功耗牆,這是這類微型化矽光元件存在的重要價值。
這其中存在的技術挑戰還是比較多,如做資料的光訊號調變的調變器調變器,據說Intel的技術使其實現了1,000倍的縮小;還有在接收端需要有個探測器(detector)轉換光訊號,用所謂的全矽微環(micro-ring)結構,實現矽對光的檢測能力;波分複用技術實現頻寬倍增,以及把矽光和CMOS晶片做整合等。
Intel認為,把矽光模組與運算資源整合,就能打破必須帶更多I/O接腳做更大尺寸處理器的這種趨勢。矽光能夠實現的是更低的功耗、更大的頻寬、更小的接腳數量和尺寸。在跨處理器、跨伺服器節點之間的資料互動上,這類技術還是頗具前景,Intel此前說目標是實現每根光纖1Tbps的速率,並且能效在1pJ/bit,最遠距離1km,這在非本地傳輸上是很理想的數字。
還有軟體…
除了AI晶片本身,從整個生態的角度,包括AI感知到運算的整個鏈條上的其他組成部分,都有促成性能和效率提升的餘地。比如這兩年Nvidia從軟體層面,針對AI運算的中間層、庫做了大量最佳化。相同的底層硬體,透過軟體最佳化就能實現幾倍的性能提升。
宋繼強說,「我們發現軟體最佳化與否,在同一個硬體上可以達到百倍的性能差距。」這其中的餘量還是比較大。
在AI開發生態上,雖然Nvidia是最具發言權的;但從戰略角度來看,像Intel這種研發CPU、GPU、FPGA、ASIC,甚至還有神經型態運算處理器的企業而言,不同處理器統一開發生態可能更具前瞻性。Intel有個稱oneAPI的軟體平台,用一套API實現不同硬體性能埠的對接。這類策略對廠商的軟體框架構建能力是非常大的考驗——也極大程度關乎底層晶片的執行效率。
在摩爾定律放緩、電晶體尺寸微縮變慢甚至不縮小的前提下,處理器架構革新、異質整合與2.5D/3D封裝技術依然可以達成1,000倍的性能提升;而一些新的技術方向,包括近記憶體運算、記憶體內運算和微型矽光,能夠在資料訪存、傳輸方面產生新的價值;神經型態運算這種類腦運算方式,是實現AI運算的目標;軟體層面的最佳化,也能夠帶動AI性能的成倍增長。所以即便摩爾定律嚴重放緩,AI晶片的性能、效率提升在上面提到的這麼多方案加持下,終將在未來很長一段時間內持續飛越。這第三(四)次科技革命恐怕還很難停歇。
資料來源:https://www.eettaiwan.com/20210726nt61-ai-computing/?fbclid=IwAR3BaorLm9rL2s1ff6cNkL6Z7dK8Q96XulQPzuMQ_Yky9H_EmLsBpjBOsWg