雖然這篇python requests動態網頁鄉民發文沒有被收入到精華區:在python requests動態網頁這個話題中,我們另外找到其它相關的精選爆讚文章
在 python產品中有4870篇Facebook貼文,粉絲數超過1,980的網紅球蟒-小龍,也在其Facebook貼文中提到, 這算是香蕉皮嗎?😂 #球蟒 #ballpython #ballpythons #ballpythonsofinstagram #python #pythonofinstagram #reptiles #爬蟲 #爬寵 #reptilesofinstagram...
同時也有4582部Youtube影片,追蹤數超過4萬的網紅吳老師教學部落格,也在其Youtube影片中提到,從EXCEL VBA到Python開發第2次上課 01_重點回顧與BMI計算 02_計算BMI與格式化到小數點第二位 03_邏輯判斷BMI的評語 04_用format格式化資料 05_用for迴圈加總1到99 06_奇數偶數分別加總 07_用step與兩個for迴圈 08_九九乘法表單列輸出 09...
「python」的推薦目錄
- 關於python 在 英國的另類日常 LittleUK.HKer Instagram 的精選貼文
- 關於python 在 Antariksha [YouTuber, Blogger] Instagram 的精選貼文
- 關於python 在 ????? ???? ♡ Instagram 的最佳解答
- 關於python 在 球蟒-小龍 Facebook 的精選貼文
- 關於python 在 PTT Gossiping 批踢踢八卦板 Facebook 的精選貼文
- 關於python 在 軟體開發學習資訊分享 Facebook 的最佳解答
- 關於python 在 吳老師教學部落格 Youtube 的最佳貼文
- 關於python 在 吳老師教學部落格 Youtube 的最讚貼文
- 關於python 在 吳老師教學部落格 Youtube 的最讚貼文
python 在 英國的另類日常 LittleUK.HKer Instagram 的精選貼文
2021-09-23 20:51:12
Well... 星期四晚發生了點小意外。。。 Y先生在家餵我地條Royal Python Nagini時,被咬到了 😬 不過Y先生有驚人的復原力, 只係過左都未夠2日, 傷口已埋得7788。 事發時已快10pm, 我和同事們吃完晚飯閒聊後在回家的途上, 還有10分鐘的路程,突然接到媽咪的電話,說...
python 在 Antariksha [YouTuber, Blogger] Instagram 的精選貼文
2021-09-24 04:13:07
@hudabeauty Wild Obsessions Python 💚 . . . . . . . . . #hudabeauty #hudabeautypython #greeneyelook #eyemakeup #editorial #eyeshadow...
python 在 ????? ???? ♡ Instagram 的最佳解答
2021-09-24 08:14:21
✨ 𝐋𝐀𝐊𝐄𝐍𝐍𝐘 ✨ Inspired by the queen @lalalalisa_m 👑 from her new music video LALISA 🤍 ♡𝐄𝐘𝐄𝐒 @hudabeauty tiger wild & python wild obsessions @colourpop...
-
python 在 吳老師教學部落格 Youtube 的最佳貼文
2021-09-27 15:21:39從EXCEL VBA到Python開發第2次上課
01_重點回顧與BMI計算
02_計算BMI與格式化到小數點第二位
03_邏輯判斷BMI的評語
04_用format格式化資料
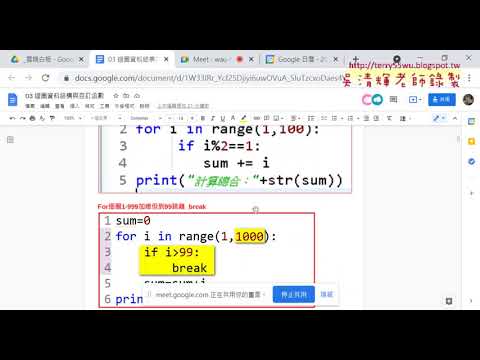
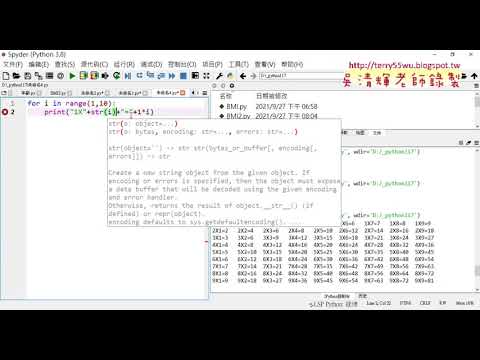
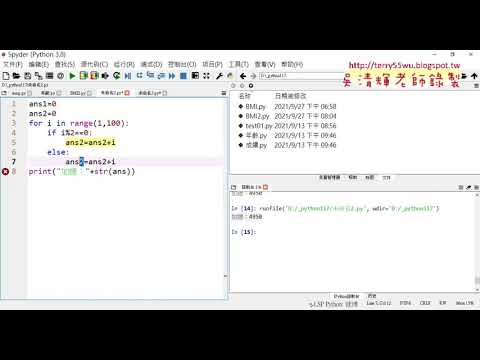
05_用for迴圈加總1到99
06_奇數偶數分別加總
07_用step與兩個for迴圈
08_九九乘法表單列輸出
09_九九乘法表多列輸出
完整教學
http://goo.gl/aQTMFS
教學論壇(之後課程會放論壇上課學員請自行加入):
https://groups.google.com/g/_vbapython117
吳老師教學論壇
http://www.tqc.idv.tw/
課程簡介:入門
建置Python開發環境
基本語法與結構控制
迴圈、資料結構及函式
VBA重要函數到Python
檔案處理
資料庫處理
課程簡介:進階
網頁資料擷取與分析、Python網頁測試自動化、YouTube影片下載器
處理 Excel 試算表、處理 PDF 與 Word 文件、處理 CSV 檔和 JSON 資料
實戰:PM2.5即時監測顯示器、Email 和文字簡訊、處理影像圖片、以 GUI 自動化來控制鍵盤和滑鼠
上課用書:
參考書目
Python初學特訓班(附250分鐘影音教學/範例程式)
作者: 鄧文淵/總監製, 文淵閣工作室/編著
出版社:碁峰 出版日期:2016/11/29
Python程式設計入門
作者:葉難
ISBN:9789864340057
出版社:博碩文化
出版日期:2015/04/02
吳老師 110/9/27
EXCEL,VBA,Python,東吳推廣部,自強工業基金會,EXCEL,VBA,函數,程式設計,線上教學,PYTHON安裝環境![post-title]()
-
python 在 吳老師教學部落格 Youtube 的最讚貼文
2021-09-27 15:21:35從EXCEL VBA到Python開發第2次上課
01_重點回顧與BMI計算
02_計算BMI與格式化到小數點第二位
03_邏輯判斷BMI的評語
04_用format格式化資料
05_用for迴圈加總1到99
06_奇數偶數分別加總
07_用step與兩個for迴圈
08_九九乘法表單列輸出
09_九九乘法表多列輸出
完整教學
http://goo.gl/aQTMFS
教學論壇(之後課程會放論壇上課學員請自行加入):
https://groups.google.com/g/_vbapython117
吳老師教學論壇
http://www.tqc.idv.tw/
課程簡介:入門
建置Python開發環境
基本語法與結構控制
迴圈、資料結構及函式
VBA重要函數到Python
檔案處理
資料庫處理
課程簡介:進階
網頁資料擷取與分析、Python網頁測試自動化、YouTube影片下載器
處理 Excel 試算表、處理 PDF 與 Word 文件、處理 CSV 檔和 JSON 資料
實戰:PM2.5即時監測顯示器、Email 和文字簡訊、處理影像圖片、以 GUI 自動化來控制鍵盤和滑鼠
上課用書:
參考書目
Python初學特訓班(附250分鐘影音教學/範例程式)
作者: 鄧文淵/總監製, 文淵閣工作室/編著
出版社:碁峰 出版日期:2016/11/29
Python程式設計入門
作者:葉難
ISBN:9789864340057
出版社:博碩文化
出版日期:2015/04/02
吳老師 110/9/27
EXCEL,VBA,Python,東吳推廣部,自強工業基金會,EXCEL,VBA,函數,程式設計,線上教學,PYTHON安裝環境![post-title]()
-
python 在 吳老師教學部落格 Youtube 的最讚貼文
2021-09-27 15:21:04從EXCEL VBA到Python開發第2次上課
01_重點回顧與BMI計算
02_計算BMI與格式化到小數點第二位
03_邏輯判斷BMI的評語
04_用format格式化資料
05_用for迴圈加總1到99
06_奇數偶數分別加總
07_用step與兩個for迴圈
08_九九乘法表單列輸出
09_九九乘法表多列輸出
完整教學
http://goo.gl/aQTMFS
教學論壇(之後課程會放論壇上課學員請自行加入):
https://groups.google.com/g/_vbapython117
吳老師教學論壇
http://www.tqc.idv.tw/
課程簡介:入門
建置Python開發環境
基本語法與結構控制
迴圈、資料結構及函式
VBA重要函數到Python
檔案處理
資料庫處理
課程簡介:進階
網頁資料擷取與分析、Python網頁測試自動化、YouTube影片下載器
處理 Excel 試算表、處理 PDF 與 Word 文件、處理 CSV 檔和 JSON 資料
實戰:PM2.5即時監測顯示器、Email 和文字簡訊、處理影像圖片、以 GUI 自動化來控制鍵盤和滑鼠
上課用書:
參考書目
Python初學特訓班(附250分鐘影音教學/範例程式)
作者: 鄧文淵/總監製, 文淵閣工作室/編著
出版社:碁峰 出版日期:2016/11/29
Python程式設計入門
作者:葉難
ISBN:9789864340057
出版社:博碩文化
出版日期:2015/04/02
吳老師 110/9/27
EXCEL,VBA,Python,東吳推廣部,自強工業基金會,EXCEL,VBA,函數,程式設計,線上教學,PYTHON安裝環境![post-title]()

python 在 球蟒-小龍 Facebook 的精選貼文
這算是香蕉皮嗎?😂
#球蟒 #ballpython #ballpythons #ballpythonsofinstagram #python #pythonofinstagram #reptiles #爬蟲 #爬寵 #reptilesofinstagram
python 在 PTT Gossiping 批踢踢八卦板 Facebook 的精選貼文
『認真回,學Python,然後
1. 把Excel資料丟到google spreadsheet上當關聯式資料庫用,
2. 用python pandas整理資料
3. 用datastudio做視覺化分析或定期觀察儀表板
這是我最推薦新手入門數據分析的工具組合。
你要做數據整理跟分析,重點只有三個:
資料存放的地方、整理資料工具語言、視覺化套件
一般來說,正規的方式是資料放sql、整理資料用sql code,
然後視覺化再用ggplot、shiny(R), Matplotlib、plotly(Python),
但初學者沒辦法一次搞懂這麼多東西,直接用現成的東西就好,
唯一需要學習的是python pandas跟如何用python串接google spreadsheet,
但這我覺得根本比VBA好學兩萬倍,code也比較好管理...』
Re: [問卦] EXCEL VBA值得花時間去學嗎 https://disp.cc/b/163-e8Nl |問卦原文 https://disp.cc/b/163-e8Gh
python 在 軟體開發學習資訊分享 Facebook 的最佳解答
--免費課程--
使用 Docker 和 Python 建立您自己的資料科學平台
https://softnshare.com/beyond-jupyter-notebooks/