雖然這篇python爬蟲動態網頁鄉民發文沒有被收入到精華區:在python爬蟲動態網頁這個話題中,我們另外找到其它相關的精選爆讚文章
在 python爬蟲動態網頁產品中有9篇Facebook貼文,粉絲數超過2萬的網紅超知識,也在其Facebook貼文中提到, 恭喜所有已經確定申請上大學的大一新鮮人!! 景超老師和超知識團隊特別為所有準大一新鮮人 設計了一系列的「未來大學必備超能力」課程 (指考戰士們不用擔心 景超在指考完也會開新的梯次喔!) 希望大家可以在下方留言 幫景超選擇你覺得想上的主題課程 (可多選) 有留言的粉絲們 可以享有超及早鳥優惠與優先報...
同時也有22部Youtube影片,追蹤數超過4萬的網紅吳老師教學部落格,也在其Youtube影片中提到,從EXCEL VBA到Python金融數據之網路爬蟲實作第13次(用IE物件下載氣溫資料標籤說明&改為下載降雨量動態切換清單&下載資料標籤重點與改成下載全部清單&增加迴圈與新增工作表與下載名稱) 01_重點回顧與用IE物件下載 02_用IE物件下載氣溫資料標籤說明 03_改為下載降雨量動態切換清單...
-
python爬蟲動態網頁 在 吳老師教學部落格 Youtube 的精選貼文
2021-01-09 06:04:21從EXCEL VBA到Python金融數據之網路爬蟲實作第13次(用IE物件下載氣溫資料標籤說明&改為下載降雨量動態切換清單&下載資料標籤重點與改成下載全部清單&增加迴圈與新增工作表與下載名稱)
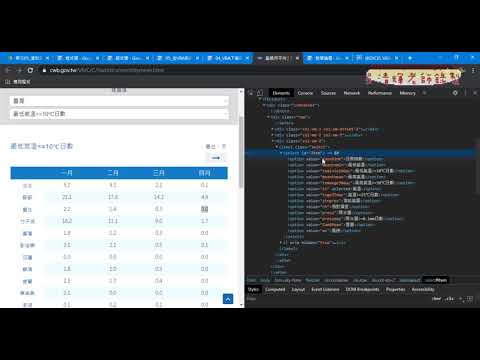
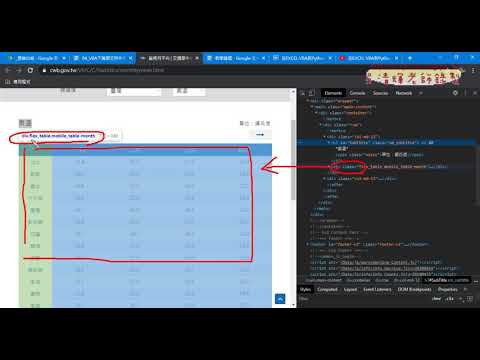
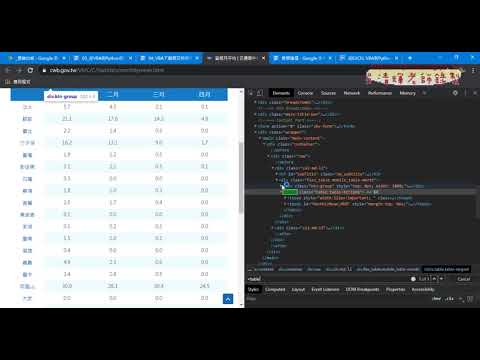
01_重點回顧與用IE物件下載
02_用IE物件下載氣溫資料標籤說明
03_改為下載降雨量動態切換清單
04_下載資料標籤重點與改成下載全部清單
05_增加迴圈與新增工作表與下載名稱
完整影音
http://goo.gl/aQTMFS
教學論壇(之後課程會放論壇上課學員請自行加入):
https://groups.google.com/forum/#!forum/labor_python_2020
懶人包:
EXCEL函數與VBA http://terry28853669.pixnet.net/blog/category/list/1384521
EXCEL VBA自動化教學 http://terry28853669.pixnet.net/blog/category/list/1384524
課程簡介:入門
VBA重要函數到Python
建置Python開發環境
基本語法與結構控制
迴圈、資料結構及函式
檔案與資料庫處理
課程簡介:進階
處理 CSV 檔和 JSON 資料
PM2.5即時監測顯示器轉存到SQLITE資料庫
網頁資料擷取與分析、
Python網頁測試自動化、
下載外匯資料、下載YAHOO股市類股、下載威力彩
EXCEL VBA與Phython協同運作
資產負債表與券商分點買賣超
群益八大公股銀行買賣超
鉅亨網新聞與MoneyDJ新聞
7-11門市與PChome
參考書目
Excel VBA實戰技巧金融數據x網路爬蟲
作者:廖敏宏(廖志煌)
出版社:碁峰 出版日期:2019/06/30
Python大數據特訓班(第二版)
作者:鄧文淵,文淵閣工作室
出版社:碁峰?出版日期:2020/06/01
吳老師 110/1/9
EXCEL,VBA,Python,東吳推廣部,自強工業基金會,EXCEL,VBA,函數,程式設計,線上教學,金融數據,網路爬蟲實作![post-title]()
-
python爬蟲動態網頁 在 吳老師教學部落格 Youtube 的最佳貼文
2021-01-09 06:04:03從EXCEL VBA到Python金融數據之網路爬蟲實作第13次(用IE物件下載氣溫資料標籤說明&改為下載降雨量動態切換清單&下載資料標籤重點與改成下載全部清單&增加迴圈與新增工作表與下載名稱)
01_重點回顧與用IE物件下載
02_用IE物件下載氣溫資料標籤說明
03_改為下載降雨量動態切換清單
04_下載資料標籤重點與改成下載全部清單
05_增加迴圈與新增工作表與下載名稱
完整影音
http://goo.gl/aQTMFS
教學論壇(之後課程會放論壇上課學員請自行加入):
https://groups.google.com/forum/#!forum/labor_python_2020
懶人包:
EXCEL函數與VBA http://terry28853669.pixnet.net/blog/category/list/1384521
EXCEL VBA自動化教學 http://terry28853669.pixnet.net/blog/category/list/1384524
課程簡介:入門
VBA重要函數到Python
建置Python開發環境
基本語法與結構控制
迴圈、資料結構及函式
檔案與資料庫處理
課程簡介:進階
處理 CSV 檔和 JSON 資料
PM2.5即時監測顯示器轉存到SQLITE資料庫
網頁資料擷取與分析、
Python網頁測試自動化、
下載外匯資料、下載YAHOO股市類股、下載威力彩
EXCEL VBA與Phython協同運作
資產負債表與券商分點買賣超
群益八大公股銀行買賣超
鉅亨網新聞與MoneyDJ新聞
7-11門市與PChome
參考書目
Excel VBA實戰技巧金融數據x網路爬蟲
作者:廖敏宏(廖志煌)
出版社:碁峰 出版日期:2019/06/30
Python大數據特訓班(第二版)
作者:鄧文淵,文淵閣工作室
出版社:碁峰?出版日期:2020/06/01
吳老師 110/1/9
EXCEL,VBA,Python,東吳推廣部,自強工業基金會,EXCEL,VBA,函數,程式設計,線上教學,金融數據,網路爬蟲實作![post-title]()
-
python爬蟲動態網頁 在 吳老師教學部落格 Youtube 的最佳解答
2021-01-09 06:03:48從EXCEL VBA到Python金融數據之網路爬蟲實作第13次(用IE物件下載氣溫資料標籤說明&改為下載降雨量動態切換清單&下載資料標籤重點與改成下載全部清單&增加迴圈與新增工作表與下載名稱)
01_重點回顧與用IE物件下載
02_用IE物件下載氣溫資料標籤說明
03_改為下載降雨量動態切換清單
04_下載資料標籤重點與改成下載全部清單
05_增加迴圈與新增工作表與下載名稱
完整影音
http://goo.gl/aQTMFS
教學論壇(之後課程會放論壇上課學員請自行加入):
https://groups.google.com/forum/#!forum/labor_python_2020
懶人包:
EXCEL函數與VBA http://terry28853669.pixnet.net/blog/category/list/1384521
EXCEL VBA自動化教學 http://terry28853669.pixnet.net/blog/category/list/1384524
課程簡介:入門
VBA重要函數到Python
建置Python開發環境
基本語法與結構控制
迴圈、資料結構及函式
檔案與資料庫處理
課程簡介:進階
處理 CSV 檔和 JSON 資料
PM2.5即時監測顯示器轉存到SQLITE資料庫
網頁資料擷取與分析、
Python網頁測試自動化、
下載外匯資料、下載YAHOO股市類股、下載威力彩
EXCEL VBA與Phython協同運作
資產負債表與券商分點買賣超
群益八大公股銀行買賣超
鉅亨網新聞與MoneyDJ新聞
7-11門市與PChome
參考書目
Excel VBA實戰技巧金融數據x網路爬蟲
作者:廖敏宏(廖志煌)
出版社:碁峰 出版日期:2019/06/30
Python大數據特訓班(第二版)
作者:鄧文淵,文淵閣工作室
出版社:碁峰?出版日期:2020/06/01
吳老師 110/1/9
EXCEL,VBA,Python,東吳推廣部,自強工業基金會,EXCEL,VBA,函數,程式設計,線上教學,金融數據,網路爬蟲實作![post-title]()

python爬蟲動態網頁 在 超知識 Facebook 的精選貼文
恭喜所有已經確定申請上大學的大一新鮮人!!
景超老師和超知識團隊特別為所有準大一新鮮人
設計了一系列的「未來大學必備超能力」課程
(指考戰士們不用擔心 景超在指考完也會開新的梯次喔!)
希望大家可以在下方留言
幫景超選擇你覺得想上的主題課程 (可多選)
有留言的粉絲們 可以享有超及早鳥優惠與優先報名的權利喔!
核心基礎能力:
(1) 零基礎OK!Python國際認證課程 (第三梯次:5/29開課 現在可以報名!)
(2) 零基礎OK!簡報製作與表達 (7月開課 未開放報名)
技術應用能力:
(3) 理工科系必備!Vpthon動態模擬分析技能
(6/26開課 現在可報名)
(4) Big Data!大數據處理特訓 (7月開課 未開放報名)
(5) Big Data!網頁爬蟲技能特訓 (7月開課 未開放報名)
(6) Big Data!Power Bi視覺化數據分析特訓 (7月開課 未開放報名)
python爬蟲動態網頁 在 台灣人工智慧學校 Facebook 的精選貼文
【三週快速入門Python】
Python是當今最流行的程式語言🔥🔥🔥,想學習又不知道該如何入手的朋友快看過來🤗🤗台灣人工智慧學校全新推出技術課程,用三週的時間,每週五、六,從最基礎的資料型態、數值運算、流程控制、函式等必備能力開始,再到進階的動態網頁爬蟲,將教大家如何利用 Python 的相關套件進行資料分析,套件包括了 NumPy、Pandas,Matplotlib 。
跟上時代系列全系列一共五堂,包含 Python、機器學習、深度學習、電腦視覺及產業應用班,將於 7 月開始陸續開課,請大家持續關注粉專與官網。
📍手刀報名Python課👉 https://bit.ly/2ANN788
📍「機器學習」課程點這邊👉 https://bit.ly/3cAkZTv
🔹 成為 AI 人才 http://bit.ly/3aufgOu
🔸 加強企業競爭力 https://bit.ly/2ZLsQuA
python爬蟲動態網頁 在 工研院產業學院 Facebook 的最讚貼文
巨量資料的行銷時代,
不讓『大數據』淪為企業轉型的口號!
《Python AI人工智慧資料分析師-專業人才養成班》
🤟入門程式設計
👉實作網路爬蟲技術
🎓分析資料
💖運用工具
想從資料分析掌握商業思維?
想體驗數據分析師的能力重點?
想用Python踏入機器學習的奧祕?
上課日期:12/7~1/19
課堂時數:66 hrs
2020跨年最佳獻禮:https://reurl.cc/QpLal2
<熱門課程推薦>
✔10/19-11/24 Python AI人工智慧資料分析師(台北班)
https://reurl.cc/EKp3Y0
---------------------------------------------
✔10/26-28【補助50%】AI深度學習理論與實作培訓班
https://reurl.cc/1Q2dqQ
---------------------------------------------
✔12/14-109/1/19 Python+Django動態網頁程式設計師
https://reurl.cc/0z25e6