雖然這篇python擷取網頁資料鄉民發文沒有被收入到精華區:在python擷取網頁資料這個話題中,我們另外找到其它相關的精選爆讚文章
在 python擷取網頁資料產品中有14篇Facebook貼文,粉絲數超過1,692的網紅吳老師excel函數與vba大數據教學,也在其Facebook貼文中提到, 從VBA的自動化到PYTHON網路爬蟲應用 https://ojt.wda.gov.tw/ClassSearch/Detail?OCID=139185&plantype=1 學費4,800 政府補助3,840 每班人數:22人,所以很快就滿了, 上課時數:30 小時 分初階與進階兩階段課程...
同時也有2086部Youtube影片,追蹤數超過4萬的網紅吳老師教學部落格,也在其Youtube影片中提到,從EXCEL VBA到Python開發第2次上課 01_重點回顧與BMI計算 02_計算BMI與格式化到小數點第二位 03_邏輯判斷BMI的評語 04_用format格式化資料 05_用for迴圈加總1到99 06_奇數偶數分別加總 07_用step與兩個for迴圈 08_九九乘法表單列輸出 09...
-
python擷取網頁資料 在 吳老師教學部落格 Youtube 的最佳解答
2021-09-27 23:21:39從EXCEL VBA到Python開發第2次上課
01_重點回顧與BMI計算
02_計算BMI與格式化到小數點第二位
03_邏輯判斷BMI的評語
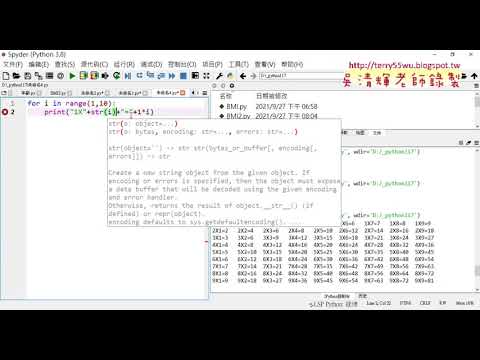
04_用format格式化資料
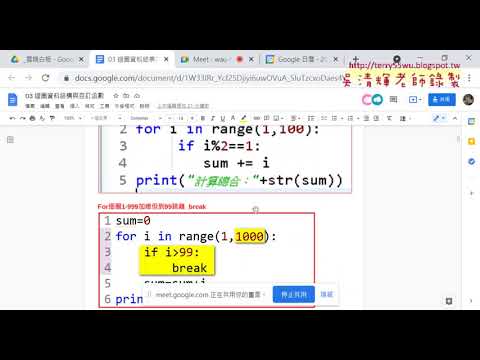
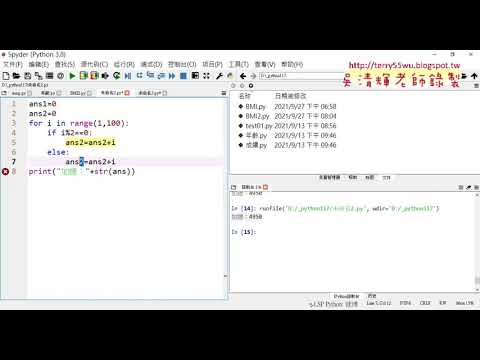
05_用for迴圈加總1到99
06_奇數偶數分別加總
07_用step與兩個for迴圈
08_九九乘法表單列輸出
09_九九乘法表多列輸出
完整教學
http://goo.gl/aQTMFS
教學論壇(之後課程會放論壇上課學員請自行加入):
https://groups.google.com/g/_vbapython117
吳老師教學論壇
http://www.tqc.idv.tw/
課程簡介:入門
建置Python開發環境
基本語法與結構控制
迴圈、資料結構及函式
VBA重要函數到Python
檔案處理
資料庫處理
課程簡介:進階
網頁資料擷取與分析、Python網頁測試自動化、YouTube影片下載器
處理 Excel 試算表、處理 PDF 與 Word 文件、處理 CSV 檔和 JSON 資料
實戰:PM2.5即時監測顯示器、Email 和文字簡訊、處理影像圖片、以 GUI 自動化來控制鍵盤和滑鼠
上課用書:
參考書目
Python初學特訓班(附250分鐘影音教學/範例程式)
作者: 鄧文淵/總監製, 文淵閣工作室/編著
出版社:碁峰 出版日期:2016/11/29
Python程式設計入門
作者:葉難
ISBN:9789864340057
出版社:博碩文化
出版日期:2015/04/02
吳老師 110/9/27
EXCEL,VBA,Python,東吳推廣部,自強工業基金會,EXCEL,VBA,函數,程式設計,線上教學,PYTHON安裝環境![post-title]()
-
python擷取網頁資料 在 吳老師教學部落格 Youtube 的最佳解答
2021-09-27 23:21:35從EXCEL VBA到Python開發第2次上課
01_重點回顧與BMI計算
02_計算BMI與格式化到小數點第二位
03_邏輯判斷BMI的評語
04_用format格式化資料
05_用for迴圈加總1到99
06_奇數偶數分別加總
07_用step與兩個for迴圈
08_九九乘法表單列輸出
09_九九乘法表多列輸出
完整教學
http://goo.gl/aQTMFS
教學論壇(之後課程會放論壇上課學員請自行加入):
https://groups.google.com/g/_vbapython117
吳老師教學論壇
http://www.tqc.idv.tw/
課程簡介:入門
建置Python開發環境
基本語法與結構控制
迴圈、資料結構及函式
VBA重要函數到Python
檔案處理
資料庫處理
課程簡介:進階
網頁資料擷取與分析、Python網頁測試自動化、YouTube影片下載器
處理 Excel 試算表、處理 PDF 與 Word 文件、處理 CSV 檔和 JSON 資料
實戰:PM2.5即時監測顯示器、Email 和文字簡訊、處理影像圖片、以 GUI 自動化來控制鍵盤和滑鼠
上課用書:
參考書目
Python初學特訓班(附250分鐘影音教學/範例程式)
作者: 鄧文淵/總監製, 文淵閣工作室/編著
出版社:碁峰 出版日期:2016/11/29
Python程式設計入門
作者:葉難
ISBN:9789864340057
出版社:博碩文化
出版日期:2015/04/02
吳老師 110/9/27
EXCEL,VBA,Python,東吳推廣部,自強工業基金會,EXCEL,VBA,函數,程式設計,線上教學,PYTHON安裝環境![post-title]()
-
python擷取網頁資料 在 吳老師教學部落格 Youtube 的精選貼文
2021-09-27 23:21:04從EXCEL VBA到Python開發第2次上課
01_重點回顧與BMI計算
02_計算BMI與格式化到小數點第二位
03_邏輯判斷BMI的評語
04_用format格式化資料
05_用for迴圈加總1到99
06_奇數偶數分別加總
07_用step與兩個for迴圈
08_九九乘法表單列輸出
09_九九乘法表多列輸出
完整教學
http://goo.gl/aQTMFS
教學論壇(之後課程會放論壇上課學員請自行加入):
https://groups.google.com/g/_vbapython117
吳老師教學論壇
http://www.tqc.idv.tw/
課程簡介:入門
建置Python開發環境
基本語法與結構控制
迴圈、資料結構及函式
VBA重要函數到Python
檔案處理
資料庫處理
課程簡介:進階
網頁資料擷取與分析、Python網頁測試自動化、YouTube影片下載器
處理 Excel 試算表、處理 PDF 與 Word 文件、處理 CSV 檔和 JSON 資料
實戰:PM2.5即時監測顯示器、Email 和文字簡訊、處理影像圖片、以 GUI 自動化來控制鍵盤和滑鼠
上課用書:
參考書目
Python初學特訓班(附250分鐘影音教學/範例程式)
作者: 鄧文淵/總監製, 文淵閣工作室/編著
出版社:碁峰 出版日期:2016/11/29
Python程式設計入門
作者:葉難
ISBN:9789864340057
出版社:博碩文化
出版日期:2015/04/02
吳老師 110/9/27
EXCEL,VBA,Python,東吳推廣部,自強工業基金會,EXCEL,VBA,函數,程式設計,線上教學,PYTHON安裝環境![post-title]()

python擷取網頁資料 在 吳老師excel函數與vba大數據教學 Facebook 的最讚貼文
從VBA的自動化到PYTHON網路爬蟲應用
https://ojt.wda.gov.tw/ClassSearch/Detail?OCID=139185&plantype=1
學費4,800 政府補助3,840
每班人數:22人,所以很快就滿了,
上課時數:30 小時
分初階與進階兩階段課程:
課程名稱:[初階]從VBA的自動化到PYTHON網路爬蟲應用
01 建置Python開發環境
02 基本語法與結構控制
03 迴圈敘述演示與資料結構及函式
04 檔案處理與SQLite資料庫處理
05 Python證照第1、2、3類:基本程式設計與選擇敘述與迴圈敘述
06 Python證照第4、5類:進階控制流程與函式(Function)
課程名稱:[進階]網頁資料擷取、分析與資料視覺化能力
07 網頁資料擷取與分析
09 實戰:處理 CSV 檔和 JSON 資料
10 實戰:PM2.5即時監測顯示器轉存資料庫
11 實戰:下載台銀外匯、下載YAHOO股市類股
12 實戰:下載威力彩開獎結果
13 Python 3網頁資料擷取與分析第1類:資料處理能力
14 Python 3第2類:網頁資料擷取與轉換
15 Python 3第3類:資料分析能力
16 Python 3第4類:資料視覺化能力
吳老師 2021/9/22
python擷取網頁資料 在 吳老師excel函數與vba大數據教學 Facebook 的最佳貼文
因應疫情,剛好可以好好學習網路爬蟲,最簡單的還是用EXCEL裡的VBA來抓資料,這個範例適用IE物件來抓取,程式可以用本來改一改就好,細節不要出錯,很快資料就全部下來了,如下。
EXCEL VBA金融數據之網路爬蟲實作16
01_下載股市資訊網與YAHOO股市
02_用IE物件下載YAHOO股市說明
03_用IE物件下載YAHOO股市細節
04_改為下載股市所有資料
05_下載資料日期用className
完整影音
http://goo.gl/aQTMFS
懶人包:
EXCEL函數與VBA http://terry28853669.pixnet.net/blog/category/list/1384521
EXCEL VBA自動化教學 http://terry28853669.pixnet.net/blog/category/list/1384524
課程簡介:入門
VBA重要函數到Python
建置Python開發環境
基本語法與結構控制
迴圈、資料結構及函式
檔案與資料庫處理
課程簡介:進階
處理 CSV 檔和 JSON 資料
PM2.5即時監測顯示器轉存到SQLITE資料庫
網頁資料擷取與分析、
Python網頁測試自動化、
下載外匯資料、下載YAHOO股市類股、下載威力彩
EXCEL VBA與Phython協同運作
資產負債表與券商分點買賣超
群益八大公股銀行買賣超
鉅亨網新聞與MoneyDJ新聞
7-11門市與PChome
參考書目
Excel VBA實戰技巧金融數據x網路爬蟲
作者:廖敏宏(廖志煌)
出版社:碁峰 出版日期:2019/06/30
Python大數據特訓班(第二版)
作者:鄧文淵,文淵閣工作室
出版社:碁峰?出版日期:2020/06/01
吳老師 110/5/22
python擷取網頁資料 在 吳老師excel函數與vba大數據教學 Facebook 的最讚貼文
[疫情學習不中斷]應學員要求整理最近VBA與Python教學課程
因應疫情關係,上實體課慢慢變的很不容易,
所以特別應許多學員的的要求,整理最近上課的課程影片,
其實也算是非同步遠距學習,一次三四小時上課,就存在一個資料夾,
所以只要一次上完三小時,並練習完畢,就等於一周課程,
也提供完整講義和練習檔,講義可以是情況列印,
按照順序,逐一學習,效果顯著,
線上學習的優點是可以反覆重複觀看教學,尤其是比較困難程式解說,
另外,也提供雲端白板資料,可以讓學員複製程式碼,
確保程式的正確性,上課若有疑問,
也可以藉由EMAIL、FB或YOUTUBE下方留言等方式提問,
只要問題明確,幾乎會在第一時間回應。。
整理的目的,主要的目的時希望學習我的課的學員都能學會,
提升上課的品質,學員只需抽空重複聽講,
並不斷練習,再將所學反覆用在工作上,
成效良好,除了效率提高外,
自己的專業技能信心提高,工作自然勝任無虞,
對未來的職涯規劃也更有希望。
最新課程整理如下,2021/5/23更新
單光碟:
光碟01_EXCEL高階函數與樞紐分析基礎班(全球人壽內訓)
光碟02_EXCEL VBA與資料庫雲端設計(入門)(東吳推廣部114)
光碟03_EXCEL VBA與資料庫雲端設計(進階)(東吳推廣部110與112)
光碟04_EXCEL VBA金融數據之網路爬蟲實作(勞工大學)
光碟05_Python程式入門202101(自強SPYDER4版)
光碟06_Python基礎程式語言證照應用班(SPYDER4版)
光碟07_[初階]從VBA的自動化到PYTHON網路爬蟲應用 (自強)
光碟08_[進階]自強網頁資料擷取、分析與資料視覺化能力 (自強)
吳老師 2021/5/23
完整連結:
https://terry55wu.blogspot.com/2021/05/vbapython.html