雖然這篇pandas寫入csv鄉民發文沒有被收入到精華區:在pandas寫入csv這個話題中,我們另外找到其它相關的精選爆讚文章
在 pandas寫入csv產品中有2篇Facebook貼文,粉絲數超過1,692的網紅吳老師excel函數與vba大數據教學,也在其Facebook貼文中提到, 終於收到最新剛出爐的 TQC+的Python3 網頁擷取與分析證照, 這是我的TQC+ Python3的第二張證照, 是1/23日考的,隔了約一個月收到。 考試主要是用Python3考四類: 第一類考CSV、XML、JSON之讀取與寫入 第二類考網頁資料擷取與轉換 第三類考nump...
同時也有2部Youtube影片,追蹤數超過4萬的網紅吳老師教學部落格,也在其Youtube影片中提到,VBA到Python程式2019開發2班第12次402市場成交行情與開檔方式&403月份統計長條圖與圓餅圖&長條圖與圓餅圖繪製多圖表&404成績統計長條圖&住宅案件統計樞紐分析表&讀取CSV檔&405樣本直方圖與散佈圖&301學生成績與產生Data Frame&讀寫EXCEL檔案到DataFrame...
-
pandas寫入csv 在 吳老師教學部落格 Youtube 的精選貼文
2019-08-07 12:14:07VBA到Python程式2019開發2班第12次402市場成交行情與開檔方式&403月份統計長條圖與圓餅圖&長條圖與圓餅圖繪製多圖表&404成績統計長條圖&住宅案件統計樞紐分析表&讀取CSV檔&405樣本直方圖與散佈圖&301學生成績與產生Data Frame&讀寫EXCEL檔案到DataFrame)
01_重點回顧與繪製圖表
02_402市場成交行情與開檔方式
03_403月份統計長條圖與圓餅圖
04_長條圖與圓餅圖繪製多圖表
05_404 成績統計長條圖(讀取CSV與計算筆數)
06_補充台北市住宅案件統計樞紐分析表
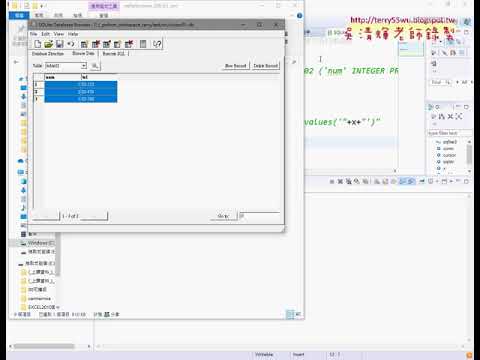
07_安裝pandas與讀取CSV檔
08_405樣本直方圖與散佈圖
09_301學生成績與產生Data Frame
10_301學生成績改為外部讀取CSV
11_傳遞參數說明與讀寫EXCEL檔案到DataFrame
完整影音
http://goo.gl/aQTMFS
教學論壇(之後課程會放論壇上課學員請自行加入):
https://groups.google.com/forum/#!forum/tcfst_python_2019_2
懶人包:
EXCEL函數與VBA http://terry28853669.pixnet.net/blog/category/list/1384521
EXCEL VBA自動化教學 http://terry28853669.pixnet.net/blog/category/list/1384524
[初階]從VBA的自動化到PYTHON網路爬蟲應用
01 建置Python開發環境 3
02 基本語法與結構控制 3
03 迴圈敘述演示與資料結構及函式 3
04 檔案處理與SQLite資料庫處理 6
05 TQC+Python證照第1、2、3類:
基本程式設計與選擇敘述與迴圈敘述 12
06 TQC+Python證照第4、5類:
進階控制流程與函式(Function) 9
[進階]網頁資料擷取、分析與資料視覺化能力
07 網頁資料擷取與分析 3
09 實戰:處理 CSV 檔和 JSON 資料 3
10 實戰:PM2.5即時監測顯示器轉存資料庫 3
11 實戰:下載台銀外匯、下載YAHOO股市類股 3
12 實戰:下載威力彩開獎結果 3
13 TQC+Python 3網頁資料擷取與分析第1類:資料處理能力 3
14 TQC+Python 3第2類:網頁資料擷取與轉換 6
15 TQC+Python 3第3類:資料分析能力 6
16 TQC+Python 3第4類:資料視覺化能力 6
上課用書:
參考書目
Python初學特訓班(附250分鐘影音教學/範例程式)
作者: 鄧文淵/總監製, 文淵閣工作室/編著
出版社:碁峰? 出版日期:2016/11/29
吳老師 108/6/21
EXCEL,VBA,Python,自強工業基金會,EXCEL,VBA,函數,程式設計,線上教學,PYTHON安裝環境,資料視覺化![post-title]()
-
pandas寫入csv 在 吳老師教學部落格 Youtube 的精選貼文
2019-08-07 12:13:19VBA到Python程式2019開發2班第12次402市場成交行情與開檔方式&403月份統計長條圖與圓餅圖&長條圖與圓餅圖繪製多圖表&404成績統計長條圖&住宅案件統計樞紐分析表&讀取CSV檔&405樣本直方圖與散佈圖&301學生成績與產生Data Frame&讀寫EXCEL檔案到DataFrame)
01_重點回顧與繪製圖表
02_402市場成交行情與開檔方式
03_403月份統計長條圖與圓餅圖
04_長條圖與圓餅圖繪製多圖表
05_404 成績統計長條圖(讀取CSV與計算筆數)
06_補充台北市住宅案件統計樞紐分析表
07_安裝pandas與讀取CSV檔
08_405樣本直方圖與散佈圖
09_301學生成績與產生Data Frame
10_301學生成績改為外部讀取CSV
11_傳遞參數說明與讀寫EXCEL檔案到DataFrame
完整影音
http://goo.gl/aQTMFS
教學論壇(之後課程會放論壇上課學員請自行加入):
https://groups.google.com/forum/#!forum/tcfst_python_2019_2
懶人包:
EXCEL函數與VBA http://terry28853669.pixnet.net/blog/category/list/1384521
EXCEL VBA自動化教學 http://terry28853669.pixnet.net/blog/category/list/1384524
[初階]從VBA的自動化到PYTHON網路爬蟲應用
01 建置Python開發環境 3
02 基本語法與結構控制 3
03 迴圈敘述演示與資料結構及函式 3
04 檔案處理與SQLite資料庫處理 6
05 TQC+Python證照第1、2、3類:
基本程式設計與選擇敘述與迴圈敘述 12
06 TQC+Python證照第4、5類:
進階控制流程與函式(Function) 9
[進階]網頁資料擷取、分析與資料視覺化能力
07 網頁資料擷取與分析 3
09 實戰:處理 CSV 檔和 JSON 資料 3
10 實戰:PM2.5即時監測顯示器轉存資料庫 3
11 實戰:下載台銀外匯、下載YAHOO股市類股 3
12 實戰:下載威力彩開獎結果 3
13 TQC+Python 3網頁資料擷取與分析第1類:資料處理能力 3
14 TQC+Python 3第2類:網頁資料擷取與轉換 6
15 TQC+Python 3第3類:資料分析能力 6
16 TQC+Python 3第4類:資料視覺化能力 6
上課用書:
參考書目
Python初學特訓班(附250分鐘影音教學/範例程式)
作者: 鄧文淵/總監製, 文淵閣工作室/編著
出版社:碁峰? 出版日期:2016/11/29
吳老師 108/6/21
EXCEL,VBA,Python,自強工業基金會,EXCEL,VBA,函數,程式設計,線上教學,PYTHON安裝環境,資料視覺化![post-title]()


pandas寫入csv 在 吳老師excel函數與vba大數據教學 Facebook 的最佳貼文
終於收到最新剛出爐的
TQC+的Python3 網頁擷取與分析證照,
這是我的TQC+ Python3的第二張證照,
是1/23日考的,隔了約一個月收到。
考試主要是用Python3考四類:
第一類考CSV、XML、JSON之讀取與寫入
第二類考網頁資料擷取與轉換
第三類考numpy 與 pandas
第四類考matplotlib視覺圖表
似乎可以把課程融入課程,但資料庫部分考的不多,
SQLite只有一題,更沒有MYSQL,有點可惜。
另外,原本以為會很難,
結果只考填空題,似乎不是那麼困難。
年後要加薪或是換跑道,
也許先考一張,會更有機會。
pandas寫入csv 在 吳老師excel函數與vba大數據教學 Facebook 的最佳解答
終於收到最新剛出爐的
TQC+的Python3 網頁擷取與分析證照,
這是我的TQC+ Python3的第二張證照,
是1/23日考的,隔了約一個月收到。
考試主要是用Python3考四類:
第一類考CSV、XML、JSON之讀取與寫入
第二類考網頁資料擷取與轉換
第三類考numpy 與 pandas
第四類考matplotlib視覺圖表
似乎可以把課程融入課程,但資料庫部分考的不多,
SQLite只有一題,更沒有MYSQL,有點可惜。
另外,原本以為會很難,
結果只考填空題,似乎不是那麼困難。
年後要加薪或是換跑道,
也許先考一張,會更有機會。