為什麼這篇Notion 繁體中文化鄉民發文收入到精華區:因為在Notion 繁體中文化這個討論話題中,有許多相關的文章在討論,這篇最有參考價值!作者ZMTL (Zaious.)看板AI_Art標題[LLMs] 台灣繁中語言模型BLOOM-zh ...
今天整理的資訊,也分享一份簡易版本在板上,
這部分自己研究自己理解會有點複雜,部分內容來自台灣智慧雲端的AI超算年會。
-
1.台灣有兩個「繁體中文語言模型」
分別是
聯發科 & 教育部國家教育研究院 & 中央研究院詞庫小組 的
BLOOM-Zh(繁體中文增強型BLOOM模型)
跟
華碩 & 科技部國家實驗研究院國家高速網路與計算中心中心 = 台灣智慧雲端 的
FFM(Formosa Foundation Model, 福爾摩沙基礎語言模型 ,或稱台智雲版的繁中BLOOM)
對,台灣的兩個繁體中文語言模型都是源自於開源的BLOOM語言模型,非純中文模型,
而且兩個模型的研發單位跟資料來源都不同,但又都同時具有官方背景。
-
2.開源的BLOOM語言模型介紹
全稱: BigScience Large Open-science Open-access Multilingual Language Model
主導公司 Hugging Face 在2022.05啟動的專案,由全球60個國家、逾250個機構,
以及超過1,000名研究人員的貢獻,最後由法國超級電腦Jean Zay執行117天的訓練而成。
https://huggingface.co/bigscience/bloom
https://images.plurk.com/2qBw9sRFznxBhnObkBiPtq.png
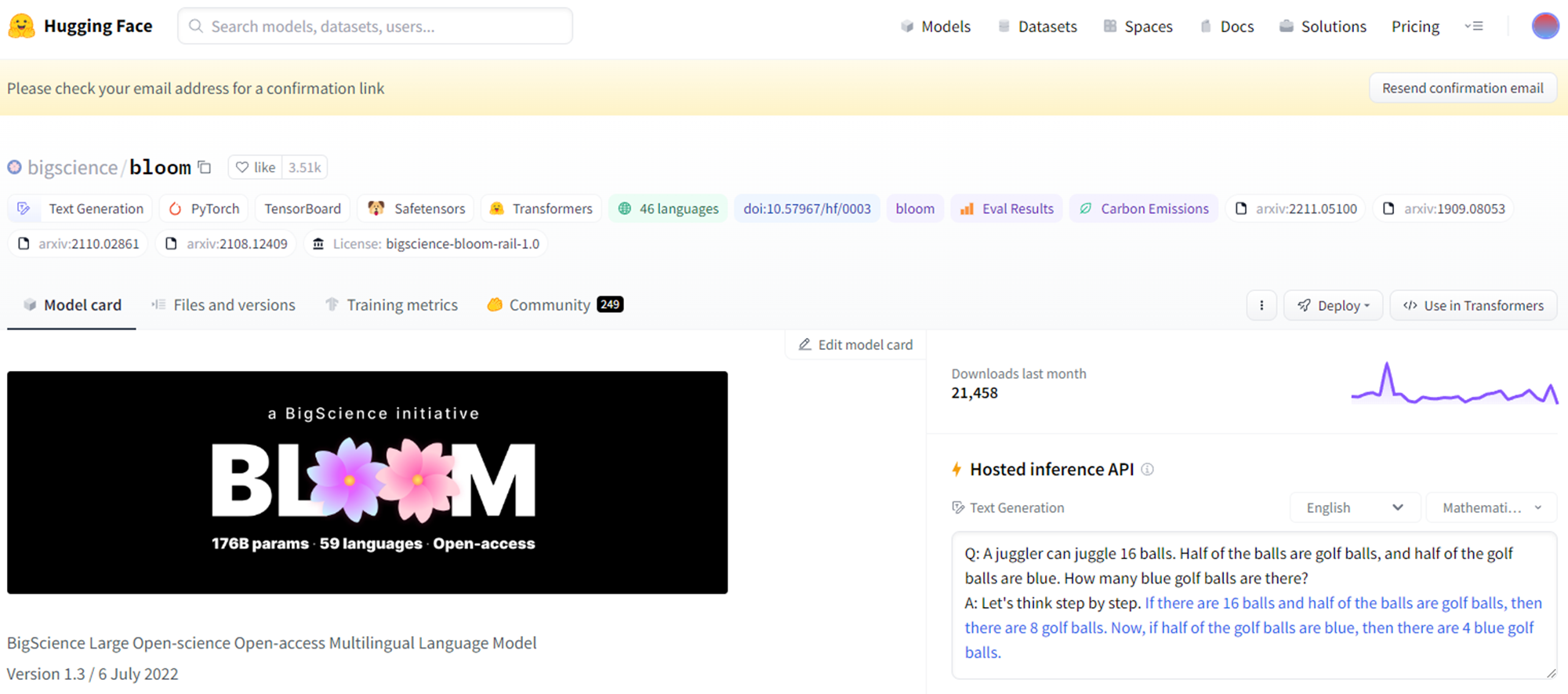
最大的版本具有 176B(1760億) 參數,對照組GPT3:175B / GPT3.5: 200B
BLOOM模型可理解46種語言及13種程式語言,包含法文、西班牙文、越南文、中文或多種
印度及非洲語言,大約只有超過30%的訓練資料為英文(但缺少德文、日文、俄文)。
能要求BLOOM撰寫食譜、翻譯或摘要,也能要求BLOOM撰寫程式碼。
https://www.ithome.com.tw/news/151935
https://edge.aif.tw/hhri-20230223-stevechen/
釋出的版本包含
BLOOM-560m / 1b1 / 1b7 / 3b / 7b1 / 176b ,b = billion,參數量
176B版本有約等於GPT3.5的同級水準。
簡體中文語料占比16.2% 繁體中文語料占比0.05%
https://images.plurk.com/7iD8Y7Dz4p6vNlUtNAPiYC.png
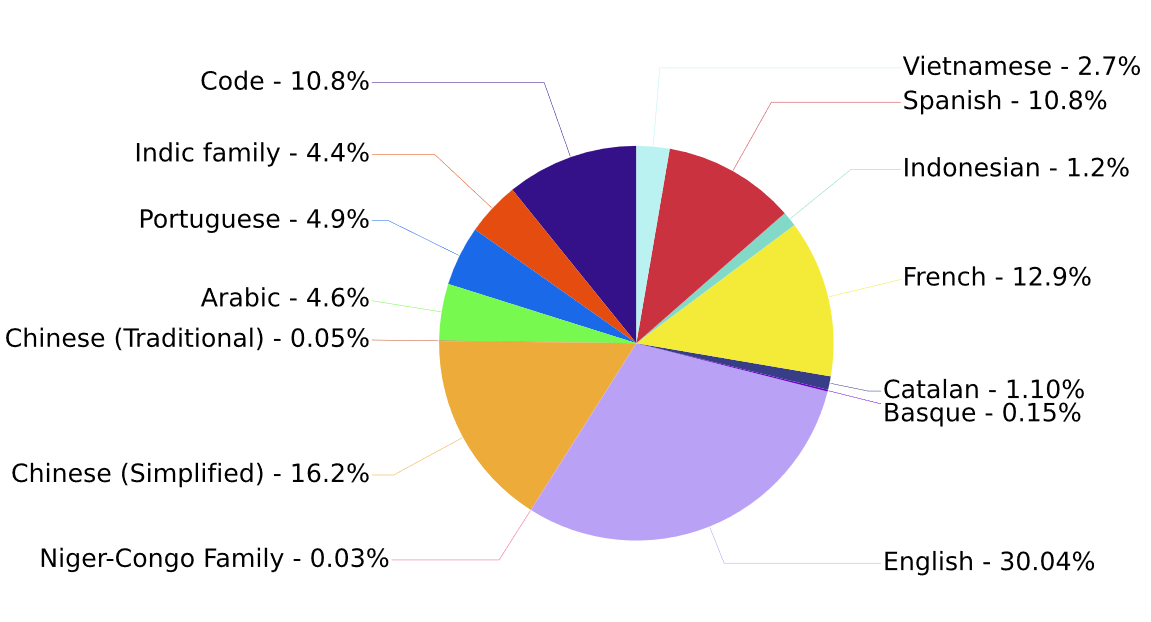
https://huggingface.co/docs/transformers/model_doc/bloom
https://huggingface.co/bigscience/bloom/blob/main/README.md
*
語言模型的開源通常包含以下內容
模型的架構:也就是該模型的基本設計,包括它是如何構建的、如何運作的等。
訓練程式 :這是用來訓練模型的程式,它定義了如何使用數據來訓練模型。
預訓練模型:這是一種已經過訓練的模型,用戶可以直接使用它來生成文本或者在特
定的任務上進行微調。
但需要注意的是,開源並不意味著訓練數據也被公開。
(以上文字from GPT4 Web Browsing)
-
3.BLOOM-Zh 語言模型介紹
第一個繁體中文(特化)語言模型,分為1b1版跟3b版,改自 BLOOM-1b1 / BLOOM-3b,
開源在 Hugging Face,也是唯一開源的繁體中文語言模型,3b版公開日期 2023.04,
預期使用情境包含問答系統、文字編修、廣告文案生成、華語教學、客服系統
https://huggingface.co/ckip-joint/bloom-3b-zh
2022年5月,聯發創新基地、中央研究院和國家教育研究院展開合作計畫,使用大型語言
模型BLOOM的繁體中文模型再訓練與優化。
聯發創新基地則建置了訓練的硬體環境,制訂各種符合國際標準的繁體中文評量指標,收
集更近期的語料,並對模型進行能更有效讀懂使用者的指示(prompt)的特別訓練。
國家教育研究院提供了大量高品質的繁體中文語料,作為主要的訓練材料。中央研究院詞
庫小組則針對模型生成的文字是否具有偏見或敵意等不合適的內容,進行自動偵測與改正
的研究與評估。
https://www.nownews.com/news/6063736
https://ezone.ulifestyle.com.hk/article/3517038
中研院詞庫小組是台灣負責研究繁體中文自然語言處理的研究單位,
曾在2019年開發並公開BERT和GPT-2的繁體中文優化版本。
具體做的事情可以參考下面這篇 【斷開中文的鎖鍊!自然語言處理 (NLP)是什麼?】
https://aiacademy.tw/what-is-nlp-natural-language-processing/
實際上效果...
https://images.plurk.com/5Nwi4czISV7b6TYLhWZxs8.png
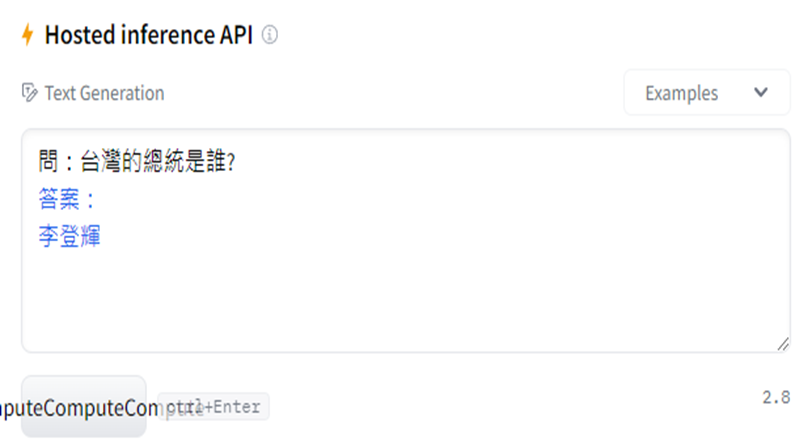
沒意外就是之前很多人說"很爛的繁中BLOOM模型"
-
4.台智雲 FFM 語言模型介紹
第一個企業級繁體中文(特化)大型語言模型,
分為7b1版跟176b版,改自 BLOOM-7b1 / BLOOM-176b,據說有個500b的版本。
正式發表於2023.05,之前都稱為台智雲(TWS)版的繁中BLOOM模型,預計2023.07上線,
僅對企業用戶,沒有打算開放民用。
https://tws.twcc.ai/ai-llm/ (未更新FFM資料)
https://www.youtube.com/watch?v=ay1AinPNaBs&t=96s (2023.02的早期介紹影片)
2018年,科技部國研院國網中心結合廣達、台灣大、華碩等三大國內企業共同組隊建造的
「雲端服務及大數據運算設施暨整合式階層儲存系統」(簡稱AI雲端平台/ 臺灣AI雲
TWCC),擁有命名為「台灣杉二號」(TAIWANIA 2)的AI超級電腦主機。
2021年2月成立,華碩集團子公司,與國家高速網路與計算中心合作,承作TWCC的維運和
銷售。華碩身為台智雲最大股東,台智雲董事長由華碩營運長謝明傑兼任,而台智雲總經理由華
碩雲端總座吳漢章擔任。
台灣大、兆豐金和永豐金合計投資共1.3億元,成為高科技業、電信資通、金融證券三強
鼎立的多元股東結構。
https://images.plurk.com/3nyYXfyUVnMTEMul6Gqbxb.png

http://www.genetinfo.com/investment/featured/item/37784.html
https://www.clarisonic.com.tw/archives/64649
資料來源是意藍資訊有限公司,
意藍資訊有限公司是一間專業在分析台灣產業與社群的公司,
幾乎囊括台灣各大社群平台的使用者公開資料,專注在產業應用與社群分析上。
https://images.plurk.com/1arTjoKZ00R82O614Tbjsc.png

https://www.eland.com.tw/
FFM Demo起來的感覺粗估有達到GPT 3.5的水準,同時對於台灣具有相當多的事實資訊,
包括台灣的地理與歷史資訊、商業品牌與市場資訊、文化資訊等等。
主打企業可以針對訓練模型、本地存放、符合台灣資安與法規需求等等。
現場一些Demo與投影片畫面:
https://images.plurk.com/2MYAIt9XLhn76VKbdGxsx0.png
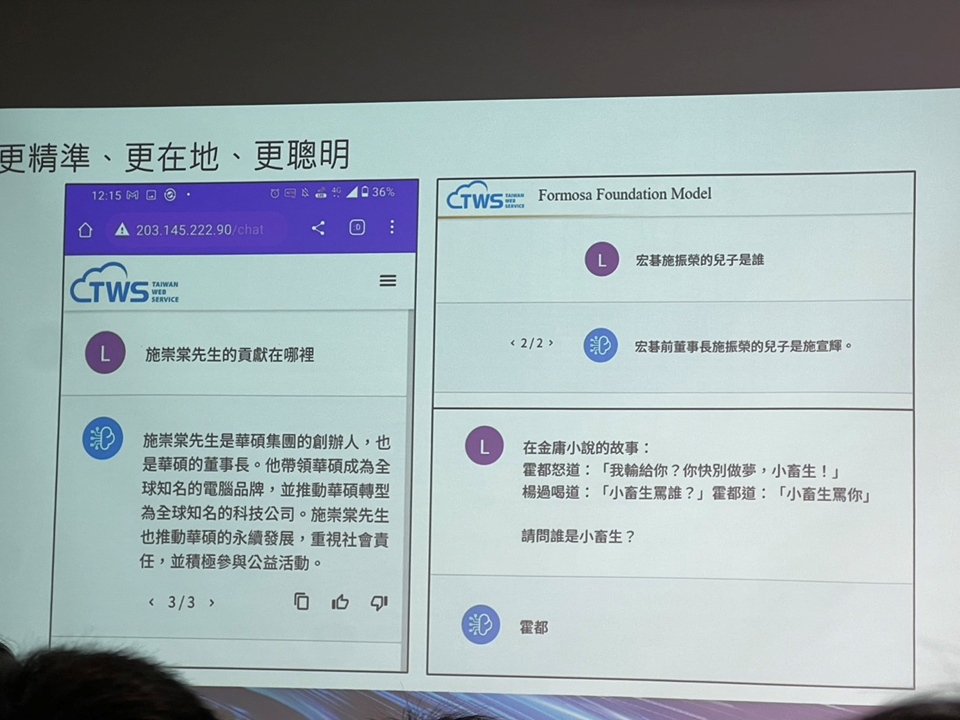


https://ithome.com.tw/news/156934
https://images.plurk.com/3oba15qvtTT00CqkFz4I6J.png







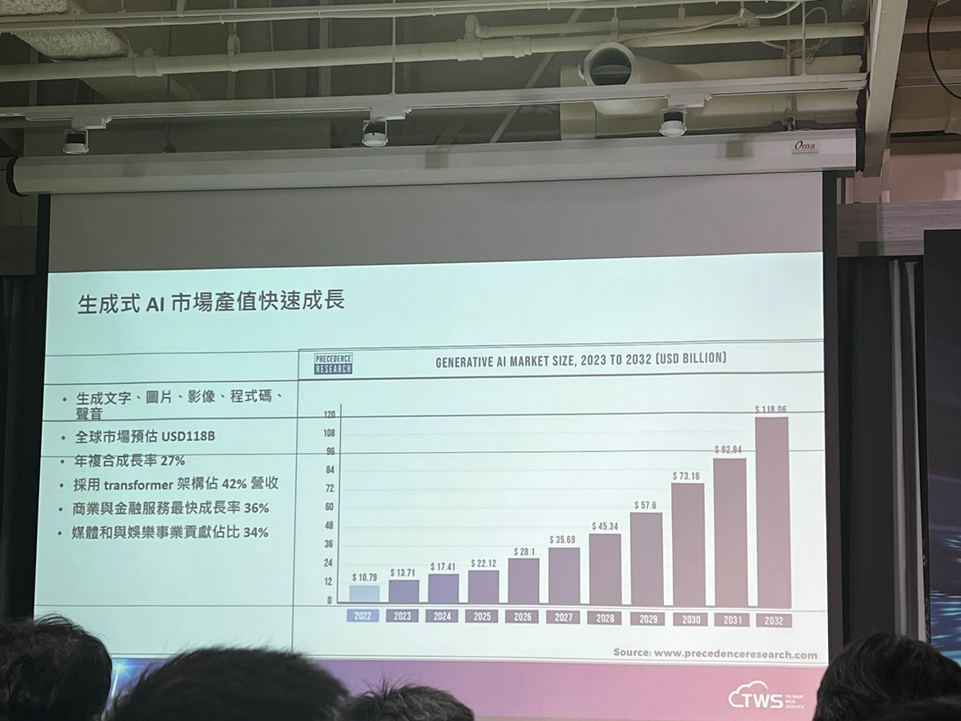
生成式AI市場數據
https://images.plurk.com/1iRdK0weumTW7deHwUYEJJ.png

剩下的整理報告我就不貼了,因為不能民用所以跟大部分的使用者其實也沒什麼關係XD
主要就是幫大家區分一下繁體中文語言模型的區別,不然讀起來很混亂。
有興趣歡迎提問。
--
AI_Art AI藝術與創作板 歡迎各方前來討論AIGC創作與相關議題!
AI情報屋營業中
噗浪:https://www.plurk.com/Zaious
IG :https://www.instagram.com/zaious.design/
日曆:https://zaious.notion.site/zaious/22c0024eceed4bdc88588b8db41e6ec4
--
※ 發信站: 批踢踢實業坊(ptt.cc), 來自: 60.250.61.231 (臺灣)
※ 文章網址: https://www.ptt.cc/bbs/AI_Art/M.1684735647.A.E3F.html
→ ZMTL: 不小心發出來了,我繼續寫XD 05/22 14:07
推 Vulpix: 用版主權限刪文可以不用清理費用的樣子。 05/22 15:32
沒差,我只是發了都發了就慢慢補完XD
※ 編輯: ZMTL (60.250.61.231 臺灣), 05/22/2023 15:35:59
推 Vulpix: 語言模型現在硬體門檻看起來還是好高,每次看到新東西我都 05/22 15:40
→ Vulpix: 只先查這個,可是好多model都不講>"< 05/22 15:41
推 tonyscat: 推分享!! 05/22 19:22
推 Destiny6: 感謝介紹,看起來只能去玩對面的了... 05/22 19:25
→ Destiny6: 略算語言模型吃多少VRAM 05/22 19:27
→ Destiny6: 例如,如果一个模型有7B个参数,那么它的FP32记忆体用 05/22 19:28
→ Destiny6: 量是28GB,而它的FP8记忆体用量是7GB。(拿BING算的) 05/22 19:28
推 avans: 推繁體語言模型介紹 05/22 21:44
推 reader2714: 最接近可以自己玩得應該是LLaMA那個譜系巴 05/22 23:16
推 Destiny6: 可以接受簡中的話倒是有好幾個中文模型,甚至還有網小 05/23 00:27
→ Destiny6: 特化跟色文的...(只查過資料,目前機器沒能力跑) 05/23 00:27
→ ZMTL: 突然想到我忘記放圖,晚點補 05/23 10:13
→ ZMTL: 大家可以推文留言有哪些有到「堪用」等級的語言模型,我可以 05/23 10:13
→ ZMTL: 去研究XD 05/23 10:13
※ 編輯: ZMTL (59.124.87.90 臺灣), 05/23/2023 11:37:47推 reader2714: alpaca好像還有中文Lora調整版 05/23 16:54
推 abc123634: 目前在日本做日文的開源 LLM,希望之後台灣也有開源且 05/23 19:41
→ abc123634: 堪用的繁體模型。感謝整理! 05/23 19:41