雖然這篇陣列定義鄉民發文沒有被收入到精華區:在陣列定義這個話題中,我們另外找到其它相關的精選爆讚文章
在 陣列定義產品中有44篇Facebook貼文,粉絲數超過3,992的網紅台灣物聯網實驗室 IOT Labs,也在其Facebook貼文中提到, 摩爾定律放緩 靠啥提升AI晶片運算力? 作者 : 黃燁鋒,EE Times China 2021-07-26 對於電子科技革命的即將終結的說法,一般認為即是指摩爾定律的終結——摩爾定律一旦無法延續,也就意味著資訊技術的整棟大樓建造都將出現停滯,那麼第三次科技革命也就正式結束了。這種聲音似乎...
同時也有50部Youtube影片,追蹤數超過1萬的網紅鍾日欣,也在其Youtube影片中提到,我是JC老師 電腦相關課程授課超過6000小時的一位AutoCAD課程講師 由於實在太多同學向JC老師反映,希望可以有線上課程學習 所以就決定錄製一系列的AutoCAD線上影片教學 而且不加密、不設限、不販售,就是純分享,希望可以幫助到有需要的朋友們 如果這部AutoCAD教學影片對你有幫助的話 請...
陣列定義 在 林凱鈞 Instagram 的最佳解答
2021-05-26 09:44:05
【凱鈞話重點-防疫】全台疫情升級拉警報!精選8大類共22款實用「防疫配件」,電子口罩、護目鏡、隨身除菌機提升防護力 📌一、一般醫療口罩 #中衛口罩 在台灣70年的知名醫療耗材製造商,CSD中衛-醫療耗材專家,製造高品質醫療口罩 #JIUJIU口罩 台灣製造MIT親親口罩,花色選擇多,符合歐...
-
陣列定義 在 鍾日欣 Youtube 的精選貼文
2021-05-05 13:24:36我是JC老師
電腦相關課程授課超過6000小時的一位AutoCAD課程講師
由於實在太多同學向JC老師反映,希望可以有線上課程學習
所以就決定錄製一系列的AutoCAD線上影片教學
而且不加密、不設限、不販售,就是純分享,希望可以幫助到有需要的朋友們
如果這部AutoCAD教學影片對你有幫助的話
請幫我按個讚,給我點鼓勵,也多分享給需要的朋友們喔~
---------------------------------------------------------------------------------------------------------
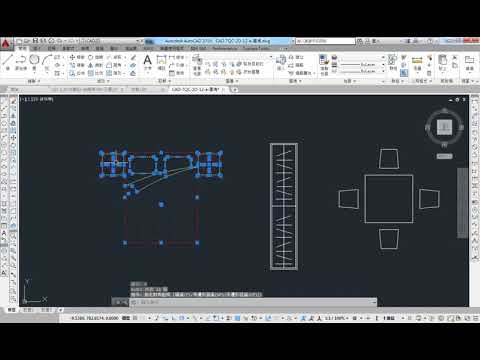
圖塊陣列MINSERT
● 在矩形陣列內插入圖塊的多個例證。
● 使用 MINSERT 插入的圖塊無法分解。
● 圖塊名稱:輸入要進行陣列的圖塊名稱。您可以在提示下輸入 ~ (波狀符號) 以顯示「選取圖檔」對話方塊。? – 列示圖塊
● 插入點:指定圖塊的位置。
● X 比例係數;設定 X 與 Y 比例係數。
● 指定旋轉角度:旋轉角度設定各個圖塊插入的角度,同時也設定整個陣列的角度。
● 列數/欄數:指定陣列中的列數和欄數。
● 列間距:指定列間距 (以單位表示)。您可以使用指向設備指定列間距,或指定兩點定義一個方塊,該方塊的寬度和高度表示列間距和欄間距。
● 欄間距:指定欄距 (單位)。
● 角點:經由使用圖塊插入點和對角點,設定比例係數。
● XYZ:設定 X、Y 與 Z 的比例係數。
● 基準點(B):在圖塊目前所在的圖面中暫時放開圖塊,然後您可在將圖塊參考拖曳至某位置時,為其指定新基準點。這不會影響為圖塊參考所定義的實際基準點。
● 比例:設定 X 軸、Y 軸與 Z 軸的比例係數。Z 軸的比例,就是指定的比例係數的絕對值。
● 旋轉(R):設定個別圖塊與整個陣列的插入角度。
● 比例(S):設定 X 軸、Y 軸與 Z 軸的比例係數。
● X:設定 X 軸的比例係數。
● Y:設定 Y 軸的比例係數。
● Z:設定 Z 軸的比例係數。
● 旋轉(R):設定圖塊的旋轉角度。
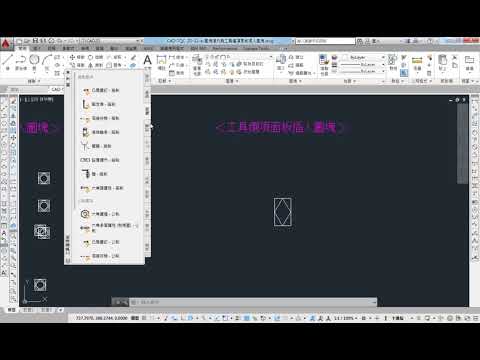
工具選項面版TOOLPALETTES(TP)(Ctrl+3)
● 工具 / 工具選項面版
● 2004的版本只能拖曳建立剖面線與圖塊,2006的版本幾乎無所不能拖曳建立
● 製作圖塊
● 儲存檔案
● 開啟工具選項面版
● 新增面板
● 拖曳所需圖塊、剖面線、工具…等至面板上
● 點下新增按鈕即可使用
---------------------------------------------------------------------------------------------------------
AutoCAD 2016 2D 線上教學影片目錄:http://bit.ly/2Y5F4Mw
AutoCAD 2016 2D 線上教學影片範例下載:https://bit.ly/3eOuKQR
AutoCAD 2D 常用快速鍵清單整理:http://bitly.com/2dUEJ9d
建築室內設計Arnold擬真呈現教學影片目錄:https://bit.ly/2VbZmmd
TQC AutoCAD 2008 2D 線上教學影片目錄:http://bitly.com/2dUGQtB
3ds Max 2015 線上教學影片目錄:http://bitly.com/2dUGqn3
JC老師個人網站:http://jc-d.net/
JC老師個人FB:https://www.facebook.com/ericjc.tw
JC-Design LINE ID:@umd7274k![post-title]()
-
陣列定義 在 鍾日欣 Youtube 的最佳解答
2021-05-05 13:10:38我是JC老師
電腦相關課程授課超過6000小時的一位AutoCAD課程講師
由於實在太多同學向JC老師反映,希望可以有線上課程學習
所以就決定錄製一系列的AutoCAD線上影片教學
而且不加密、不設限、不販售,就是純分享,希望可以幫助到有需要的朋友們
如果這部AutoCAD教學影片對你有幫助的話
請幫我按個讚,給我點鼓勵,也多分享給需要的朋友們喔~
---------------------------------------------------------------------------------------------------------
圖塊使用步驟
● 用1:1繪製圖塊輪廓
● 製作圖塊
◆ 寫出圖塊WBLOCK(W)
◆ 建立圖塊BLOCK(B)
● 使用圖塊
◆ 插入INSERT(I)
◆ 等分DIVIDE(DIV)
◆ 等距MEASURE(ME)
◆ 快速引線QLEADER(LE)
◆ 表格TABLE(TB)
◆ 工具選項面版TOOLPALETTES(TP)(Ctrl+3)
◆ 圖塊陣列MINSERT
◆ 設計中心ADCENTER(ADC)
建立圖塊BLOCK(B)
● 「常用」頁籤 /「圖塊」面板 /「建立」。
● 「插入」頁籤 /「圖塊定義」面板 /「建立」。
● 從所選物件建立圖塊定義
● 選取物件
● 執行指令
● 輸入名稱
● 指定基準點(很重要)
● 保留:原圖形保留,不轉換成圖塊或是刪除
● 轉換成圖塊:將圖形轉成圖塊
● 刪除:轉成圖塊後刪除原圖形
● 描述:可以省略
● 在圖塊圖塊編輯器中開啟:設定動態圖塊
---------------------------------------------------------------------------------------------------------
AutoCAD 2016 2D 線上教學影片目錄:http://bit.ly/2Y5F4Mw
AutoCAD 2016 2D 線上教學影片範例下載:https://bit.ly/3eOuKQR
AutoCAD 2D 常用快速鍵清單整理:http://bitly.com/2dUEJ9d
建築室內設計Arnold擬真呈現教學影片目錄:https://bit.ly/2VbZmmd
TQC AutoCAD 2008 2D 線上教學影片目錄:http://bitly.com/2dUGQtB
3ds Max 2015 線上教學影片目錄:http://bitly.com/2dUGqn3
JC老師個人網站:http://jc-d.net/
JC老師個人FB:https://www.facebook.com/ericjc.tw
JC-Design LINE ID:@umd7274k![post-title]()
-
陣列定義 在 鍾日欣 Youtube 的最讚貼文
2021-05-03 13:05:54我是JC老師
電腦相關課程授課超過6000小時的一位AutoCAD課程講師
由於實在太多同學向JC老師反映,希望可以有線上課程學習
所以就決定錄製一系列的AutoCAD線上影片教學
而且不加密、不設限、不販售,就是純分享,希望可以幫助到有需要的朋友們
如果這部AutoCAD教學影片對你有幫助的話
請幫我按個讚,給我點鼓勵,也多分享給需要的朋友們喔~
---------------------------------------------------------------------------------------------------------
矩形陣列ARRAYRECT
● 將物件複本分配到任何列、欄和圖層的組合。
● 選取物件
● 關聯式(AS):指定陣列物件為關聯式或獨立
◆ 是(Y):將陣列項目納入單一陣列物件中,類似於圖塊。透過關聯式陣列,您可以編輯性質和來源物件以快速將變更擴展至整個陣列。
◆ 否(N):以獨立物件的形式建立陣列項目。對某個項目的變更並不會影響其他項目。
● 基準點(B):定義陣列基準點和基準點掣點的位置
● 關鍵點(K):對於關聯式陣列,請在來源物件上指定一個有效的約束點 (或關鍵點),將其與路徑對齊。如果您編輯結果陣列的來源物件或路徑,陣列的基準點會保持和來源物件的關鍵點重合。
● 行數(COL)
◆ 輸入行數
◆ 輸入行距[總計(T) /表示式(E)]
● 列數(R)
◆ 輸入列數
◆ 輸入列距[總計(T) /表示式(E)]
◆ 指定列之增量高程
● 間距(S)
◆ 輸入行距
◆ 輸入列距
● 計數(COU)
◆ 輸入行數
◆ 輸入列數
● 圖層(L):指定 3D 陣列的圖層數量和間距
◆ 圖層數:指定陣列中的圖層數
◆ 圖層之間的距離:指定每個物件的相等位置之間 Z 座標值的差值
◆ 總長:在第一個和最後一個圖層中,指定物件的相等位置之間 Z 座標值的總差值
◆ 表示式:根據數學公式或方程式導出值
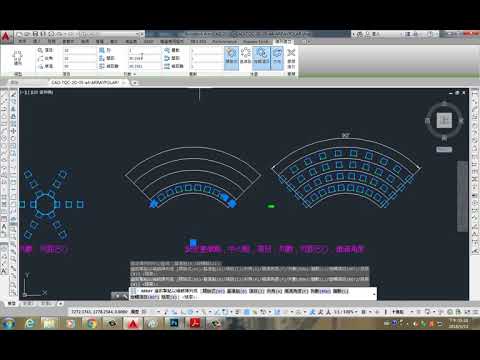
環形陣列ARRAYPOLAR
● 繞著中心點或旋轉軸以圓形樣式均勻分配物件複本。
● 選取物件:選取要在陣列中使用的物件。
● 中心點:指定一個點,以將陣列項目分配於該點周圍。旋轉軸為目前 UCS 的 Z 軸。
◆ 基準點(B):指定陣列的基準點。
◆ 旋轉軸(A):指定由兩個指定點所定義的自訂旋轉軸。
● 關聯式(AS):指定陣列物件為關聯式或獨立。
◆ 是(Y):將陣列項目納入單一陣列物件中,類似於圖塊。透過關聯式陣列,您可以編輯性質和來源物件以快速將變更擴展至整個陣列。
◆ 否(N):以獨立物件的形式建立陣列項目。對某個項目的變更並不會影響其他項目。
● 項目(I):使用值或表示式指定陣列中的項目數目。
● 夾角:使用值或表示式指定項目之間的角度。
● 填滿角度:使用值或表示式指定陣列中第一個和最後一個項目之間的角度。
● 旋轉項目(ROT):控制是否旋轉陣列的項目。
● 列數(ROW):設定列數。
◆ 列間距:從每個物件上的對等位置測量,指定各列之間的距離。
◆ 總長(T):從起點與終點物件上的對等位置測量,指定起點和終點列之間的總距離。
◆ 增量高程:設定後續每一列的增加或減少高程。
◆ 表示式:根據數學公式或方程式導出值。
● 圖層(L):指定圖層的數量和間距 (用於 3D 陣列)。
◆ 圖層數:指定陣列中的圖層數。
◆ 圖層之間的距離:指定圖層之間的距離。
◆ 表示式:使用數學公式或方程式衍生出值。
◆ 總長:指定第一個圖層和最後一個圖層之間的總距離。
路徑陣列ARRAYPATH
● 沿著路徑或部分路徑分配物件複本
● 路徑可以是直線、聚合線、3D 聚合線、雲形線、螺旋線、弧、圓或橢圓。
● 選取物件
● 選取路徑曲線
● 關聯式(AS):指定陣列物件為關聯式或獨立。
◆ 是(Y):將陣列項目納入單一陣列物件中,類似於圖塊。透過關聯式陣列,您可以編輯性質和來源物件以快速將變更擴展至整個陣列。
◆ 否(N):以獨立物件的形式建立陣列項目。對某個項目的變更並不會影響其他項目。
● 方式(M):沿著路徑分配項目的控制方法
◆ 等分(D):沿著路徑長度均勻分配指定數目的項目
◆ 等距(M):沿著路徑依指定間隔分配項目
● 基準點(B):指定一個基準點,以相對於路徑曲線起點來放置陣列中的項目。
● 關鍵點:對於關聯式陣列,請在來源物件上指定一個有效的約束點 (或關鍵點),將其與路徑對齊。如果您編輯結果陣列的來源物件或路徑,陣列的基準點會保持和來源物件的關鍵點重合。
● 切線方向(T):指定兩個點,表示陣列項目相對於路徑的切向。這兩點的向量可建立陣列中第一個項目的切向。「對齊項目」設定控制陣列中的其他項目是否保持相切或平行方位。
● 項目(I):根據「方法」設定指定項目數目或項目之間的距離。
◆ 列數(ROW):設定列數。
◆ 列間距:從每個物件上的對等位置測量,指定各列之間的距離。
◆ 總長(T):從起點與終點物件上的對等位置測量,指定起點和終點列之間的總距離。
◆ 增量高程:設定後續每一列的增加或減少高程。
◆ 表示式:根據數學公式或方程式導出值。
● 圖層(L):指定圖層的數量和間距 (用於 3D 陣列)。
◆ 圖層數:指定陣列中的圖層數。
◆ 圖層之間的距離:指定圖層之間的距離。
◆ 表示式:使用數學公式或方程式衍生出值。
◆ 總長:指定第一個圖層和最後一個圖層之間的總距離。
● Z 方向(Z);控制是否保留項目原始的 Z 方向或是沿著 3D 路徑自然排列項目。
---------------------------------------------------------------------------------------------------------
AutoCAD 2016 2D 線上教學影片目錄:http://bit.ly/2Y5F4Mw
AutoCAD 2016 2D 線上教學影片範例下載:https://bit.ly/3eOuKQR
AutoCAD 2D 常用快速鍵清單整理:http://bitly.com/2dUEJ9d
建築室內設計Arnold擬真呈現教學影片目錄:https://bit.ly/2VbZmmd
TQC AutoCAD 2008 2D 線上教學影片目錄:http://bitly.com/2dUGQtB
3ds Max 2015 線上教學影片目錄:http://bitly.com/2dUGqn3
JC老師個人網站:http://jc-d.net/
JC老師個人FB:https://www.facebook.com/ericjc.tw
JC-Design LINE ID:@umd7274k![post-title]()

陣列定義 在 台灣物聯網實驗室 IOT Labs Facebook 的精選貼文
摩爾定律放緩 靠啥提升AI晶片運算力?
作者 : 黃燁鋒,EE Times China
2021-07-26
對於電子科技革命的即將終結的說法,一般認為即是指摩爾定律的終結——摩爾定律一旦無法延續,也就意味著資訊技術的整棟大樓建造都將出現停滯,那麼第三次科技革命也就正式結束了。這種聲音似乎是從十多年前就有的,但這波革命始終也沒有結束。AI技術本質上仍然是第三次科技革命的延續……
人工智慧(AI)的技術發展,被很多人形容為第四次科技革命。前三次科技革命,分別是蒸汽、電氣、資訊技術(電子科技)革命。彷彿這“第四次”有很多種說辭,比如有人說第四次科技革命是生物技術革命,還有人說是量子技術革命。但既然AI也是第四次科技革命之一的候選技術,而且作為資訊技術的組成部分,卻又獨立於資訊技術,即表示它有獨到之處。
電子科技革命的即將終結,一般認為即是指摩爾定律的終結——摩爾定律一旦無法延續,也就意味著資訊技術的整棟大樓建造都將出現停滯,那麼第三次科技革命也就正式結束了。這種聲音似乎是從十多年前就有,但這波革命始終也沒有結束。
AI技術本質上仍然是第三次科技革命的延續,它的發展也依託於幾十年來半導體科技的進步。這些年出現了不少專門的AI晶片——而且市場參與者相眾多。當某一個類別的技術發展到出現一種專門的處理器為之服務的程度,那麼這個領域自然就不可小覷,就像當年GPU出現專門為圖形運算服務一樣。
所以AI晶片被形容為CPU、GPU之後的第三大類電腦處理器。AI專用處理器的出現,很大程度上也是因為摩爾定律的發展進入緩慢期:電晶體的尺寸縮減速度,已經無法滿足需求,所以就必須有某種專用架構(DSA)出現,以快速提升晶片效率,也才有了專門的AI晶片。
另一方面,摩爾定律的延緩也成為AI晶片發展的桎梏。在摩爾定律和登納德縮放比例定律(Dennard Scaling)發展的前期,電晶體製程進步為晶片帶來了相當大的助益,那是「happy scaling down」的時代——CPU、GPU都是這個時代受益,不過Dennard Scaling早在45nm時期就失效了。
AI晶片作為第三大類處理器,在這波發展中沒有趕上happy scaling down的好時機。與此同時,AI應用對運算力的需求越來越貪婪。今年WAIC晶片論壇圓桌討論環節,燧原科技創始人暨CEO趙立東說:「現在訓練的GPT-3模型有1750億參數,接近人腦神經元數量,我以為這是最大的模型了,要千張Nvidia的GPU卡才能做。談到AI運算力需求、模型大小的問題,說最大模型超過萬億參數,又是10倍。」
英特爾(Intel)研究院副總裁、中國研究院院長宋繼強說:「前兩年用GPU訓練一個大規模的深度學習模型,其碳排放量相當於5台美式車整個生命週期產生的碳排量。」這也說明了AI運算力需求的貪婪,以及提供運算力的AI晶片不夠高效。
不過作為產業的底層驅動力,半導體製造技術仍源源不斷地為AI發展提供推力。本文將討論WAIC晶片論壇上聽到,針對這個問題的一些前瞻性解決方案——有些已經實現,有些則可能有待時代驗證。
XPU、摩爾定律和異質整合
「電腦產業中的貝爾定律,是說能效每提高1,000倍,就會衍生出一種新的運算形態。」中科院院士劉明在論壇上說,「若每瓦功耗只能支撐1KOPS的運算,當時的這種運算形態是超算;到了智慧型手機時代,能效就提高到每瓦1TOPS;未來的智慧終端我們要達到每瓦1POPS。 這對IC提出了非常高的要求,如果依然沿著CMOS這條路去走,當然可以,但會比較艱辛。」
針對性能和效率提升,除了尺寸微縮,半導體產業比較常見的思路是電晶體結構、晶片結構、材料等方面的最佳化,以及處理架構的革新。
(1)AI晶片本身其實就是對處理器架構的革新,從運算架構的層面來看,針對不同的應用方向造不同架構的處理器是常規,更專用的處理器能促成效率和性能的成倍增長,而不需要依賴於電晶體尺寸的微縮。比如GPU、神經網路處理器(NPU,即AI處理器),乃至更專用的ASIC出現,都是這類思路。
CPU、GPU、NPU、FPGA等不同類型的晶片各司其職,Intel這兩年一直在推行所謂的「XPU」策略就是用不同類型的處理器去做不同的事情,「整合起來各取所需,用組合拳會好過用一種武器去解決所有問題。」宋繼強說。Intel的晶片產品就涵蓋了幾個大類,Core CPU、Xe GPU,以及透過收購獲得的AI晶片Habana等。
另外針對不同類型的晶片,可能還有更具體的最佳化方案。如當代CPU普遍加入AVX512指令,本質上是特別針對深度學習做加強。「專用」的不一定是處理器,也可以是處理器內的某些特定單元,甚至固定功能單元,就好像GPU中加入專用的光線追蹤單元一樣,這是當代處理器普遍都在做的一件事。
(2)從電晶體、晶片結構層面來看,電晶體的尺寸現在仍然在縮減過程中,只不過縮減幅度相比過去變小了——而且為緩解電晶體性能的下降,需要有各種不同的技術來輔助尺寸變小。比如說在22nm節點之後,電晶體變為FinFET結構,在3nm之後,電晶體即將演變為Gate All Around FET結構。最終會演化為互補FET (CFET),其本質都是電晶體本身充分利用Z軸,來實現微縮性能的提升。
劉明認為,「除了基礎元件的變革,IC現在的發展還是比較多元化,包括新材料的引進、元件結構革新,也包括微影技術。長期賴以微縮的基本手段,現在也在發生巨大的變化,特別是未來3D的異質整合。這些多元技術的協同發展,都為晶片整體性能提升帶來了很好的增益。」
他並指出,「從電晶體級、到晶圓級,再到晶片堆疊、引線接合(lead bonding),精準度從毫米向奈米演進,互連密度大大提升。」從晶圓/裸晶的層面來看,則是眾所周知的朝more than moore’s law這樣的路線發展,比如把兩片裸晶疊起來。現在很熱門的chiplet技術就是比較典型的並不依賴於傳統電晶體尺寸微縮,來彈性擴展性能的方案。
台積電和Intel這兩年都在大推將不同類型的裸晶,異質整合的技術。2.5D封裝方案典型如台積電的CoWoS,Intel的EMIB,而在3D堆疊上,Intel的Core LakeField晶片就是用3D Foveros方案,將不同的裸晶疊在一起,甚至可以實現兩片運算裸晶的堆疊、互連。
之前的文章也提到過AMD剛發佈的3D V-Cache,將CPU的L3 cache裸晶疊在運算裸晶上方,將處理器的L3 cache大小增大至192MB,對儲存敏感延遲應用的性能提升。相比Intel,台積電這項技術的獨特之處在於裸晶間是以混合接合(hybrid bonding)的方式互連,而不是micro-bump,做到更小的打線間距,以及晶片之間數十倍通訊性能和效率提升。
這些方案也不直接依賴傳統的電晶體微縮方案。這裡實際上還有一個方面,即新材料的導入專家們沒有在論壇上多說,本文也略過不談。
1,000倍的性能提升
劉明談到,當電晶體微縮的空間沒有那麼大的時候,產業界傾向於採用新的策略來評價技術——「PPACt」——即Powe r(功耗)、Performance (性能)、Cost/Area-Time (成本/面積-時間)。t指的具體是time-to-market,理論上應該也屬於成本的一部分。
電晶體微縮方案失效以後,「多元化的技術變革,依然會讓IC性能得到進一步的提升。」劉明說,「根據預測,這些技術即使不再做尺寸微縮,也會讓IC的晶片性能做到500~1,000倍的提升,到2035年實現Zetta Flops的系統性能水準。且超算的發展還可以一如既往地前進;單裸晶儲存容量變得越來越大,IC依然會為產業發展提供基礎。」
500~1,000倍的預測來自DARPA,感覺有些過於樂觀。因為其中的不少技術存在比較大的邊際遞減效應,而且有更實際的工程問題待解決,比如運算裸晶疊層的散熱問題——即便業界對於這類工程問題的探討也始終在持續。
不過1,000倍的性能提升,的確說明摩爾定律的終結並不能代表第三次科技革命的終結,而且還有相當大的發展空間。尤其本文談的主要是AI晶片,而不是更具通用性的CPU。
矽光、記憶體內運算和神經型態運算
在非傳統發展路線上(以上內容都屬於半導體製造的常規思路),WAIC晶片論壇上宋繼強和劉明都提到了一些頗具代表性的技術方向(雖然這可能與他們自己的業務方向或研究方向有很大的關係)。這些技術可能尚未大規模推廣,或者仍在商業化的極早期。
(1)近記憶體運算和記憶體內運算:處理器性能和效率如今面臨的瓶頸,很大程度並不在單純的運算階段,而在資料傳輸和儲存方面——這也是共識。所以提升資料的傳輸和存取效率,可能是提升整體系統性能時,一個非常靠譜的思路。
這兩年市場上的處理器產品用「近記憶體運算」(near-memory computing)思路的,應該不在少數。所謂的近記憶體運算,就是讓儲存(如cache、memory)單元更靠近運算單元。CPU的多層cache結構(L1、L2、L3),以及電腦處理器cache、記憶體、硬碟這種多層儲存結構是常規。而「近記憶體運算」主要在於究竟有多「近」,cache記憶體有利於隱藏當代電腦架構中延遲和頻寬的局限性。
這兩年在近記憶體運算方面比較有代表性的,一是AMD——比如前文提到3D V-cache增大處理器的cache容量,還有其GPU不僅在裸晶內導入了Infinity Cache這種類似L3 cache的結構,也更早應用了HBM2記憶體方案。這些實踐都表明,儲存方面的革新的確能帶來性能的提升。
另外一個例子則是Graphcore的IPU處理器:IPU的特點之一是在裸晶內堆了相當多的cache資源,cache容量遠大於一般的GPU和AI晶片——也就避免了頻繁的訪問外部儲存資源的操作,極大提升頻寬、降低延遲和功耗。
近記憶體運算的本質仍然是馮紐曼架構(Von Neumann architecture)的延續。「在做處理的過程中,多層級的儲存結構,資料的搬運不僅僅在處理和儲存之間,還在不同的儲存層級之間。這樣頻繁的資料搬運帶來了頻寬延遲、功耗的問題。也就有了我們經常說的運算體系內的儲存牆的問題。」劉明說。
構建非馮(non-von Neumann)架構,把傳統的、以運算為中心的馮氏架構,變換一種新的運算範式。把部分運算力下推到儲存。這便是記憶體內運算(in-memory computing)的概念。
記憶體內運算的就現在看來還是比較新,也有稱其為「存算一體」。通常理解為在記憶體中嵌入演算法,儲存單元本身就有運算能力,理論上消除資料存取的延遲和功耗。記憶體內運算這個概念似乎這在資料爆炸時代格外醒目,畢竟可極大減少海量資料的移動操作。
其實記憶體內運算的概念都還沒有非常明確的定義。現階段它可能的內涵至少涉及到在儲記憶體內部,部分執行資料處理工作;主要應用於神經網路(因為非常契合神經網路的工作方式),以及這類晶片具體的工作方法上,可能更傾向於神經型態運算(neuromorphic computing)。
對於AI晶片而言,記憶體內運算的確是很好的思路。一般的GPU和AI晶片執行AI負載時,有比較頻繁的資料存取操作,這對性能和功耗都有影響。不過記憶體內運算的具體實施方案,在市場上也是五花八門,早期比較具有代表性的Mythic導入了一種矩陣乘的儲存架構,用40nm嵌入式NOR,在儲記憶體內部執行運算,不過替換掉了數位週邊電路,改用類比的方式。在陣列內部進行模擬運算。這家公司之前得到過美國國防部的資金支援。
劉明列舉了近記憶體運算和記憶體內運算兩種方案的例子。其中,近記憶體運算的這個方案應該和AMD的3D V-cache比較類似,把儲存裸晶和運算裸晶疊起來。
劉明指出,「這是我們最近的一個工作,採用hybrid bonding的技術,與矽通孔(TSV)做比較,hybrid bonding功耗是0.8pJ/bit,而TSV是4pJ/bit。延遲方面,hybrid bonding只有0.5ns,而TSV方案是3ns。」台積電在3D堆疊方面的領先優勢其實也體現在hybrid bonding混合鍵合上,前文也提到了它具備更高的互連密度和效率。
另外這套方案還將DRAM刷新頻率提高了一倍,從64ms提高至128ms,以降低功耗。「應對刷新率變慢出現拖尾bit,我們引入RRAM TCAM索引這些tail bits」劉明說。
記憶體內運算方面,「傳統運算是用布林邏輯,一個4位元的乘法需要用到幾百個電晶體,這個過程中需要進行資料來回的移動。記憶體內運算是利用單一元件的歐姆定律來完成一次乘法,然後利用基爾霍夫定律完成列的累加。」劉明表示,「這對於今天深度學習的矩陣乘非常有利。它是原位的運算和儲存,沒有資料搬運。」這是記憶體內運算的常規思路。
「無論是基於SRAM,還是基於新型記憶體,相比近記憶體運算都有明顯優勢,」劉明認為。下圖是記憶體內運算和近記憶體運算,精準度、能效等方面的對比,記憶體內運算架構對於低精準度運算有價值。
下圖則總結了業內主要的一些記憶體內運算研究,在精確度和能效方面的對應關係。劉明表示,「需要高精確度、高運算力的情況下,近記憶體運算目前還是有優勢。不過記憶體內運算是更新的技術,這幾年的進步也非常快。」
去年阿里達摩院發佈2020年十大科技趨勢中,有一個就是存算一體突破AI算力瓶頸。不過記憶體內運算面臨的商用挑戰也一點都不小。記憶體內運算的通常思路都是類比電路的運算方式,這對記憶體、運算單元設計都需要做工程上的考量。與此同時這樣的晶片究竟由誰來造也是個問題:是記憶體廠商,還是數文書處理器廠商?(三星推過記憶體內運算晶片,三星、Intel垂直整合型企業似乎很適合做記憶體內運算…)
(2)神經型態運算:神經型態運算和記憶體內運算一樣,也是新興技術的熱門話題,這項技術有時也叫作compute in memory,可以認為它是記憶體內運算的某種發展方向。神經型態和一般神經網路AI晶片的差異是,這種結構更偏「類人腦」。
進行神經型態研究的企業現在也逐漸變得多起來,劉明也提到了AI晶片「最終的理想是在結構層次模仿腦,元件層次逼近腦,功能層次超越人腦」的「類腦運算」。Intel是比較早關注神經型態運算研究的企業之一。
傳說中的Intel Loihi就是比較典型存算一體的架構,「這片裸晶裡面包含128個小核心,每個核心用於模擬1,024個神經元的運算結構。」宋繼強說,「這樣一塊晶片大概可以類比13萬個神經元。我們做到的是把768個晶片再連起來,構成接近1億神經元的系統,讓學術界的夥伴去試用。」
「它和深度學習加速器相比,沒有任何浮點運算——就像人腦裡面沒有乘加器。所以其學習和訓練方法是採用一種名為spike neutral network的路線,功耗很低,也可以訓練出做視覺辨識、語言辨識和其他種類的模型。」宋繼強認為,不採用同步時脈,「刺激的時候就是一個非同步電動勢,只有工作部分耗電,功耗是現在深度學習加速晶片的千分之一。」
「而且未來我們可以對不同區域做劃分,比如這兒是視覺區、那兒是語言區、那兒是觸覺區,同時進行多模態訓練,互相之間產生關聯。這是現在的深度學習模型無法比擬的。」宋繼強說。這種神經型態運算晶片,似乎也是Intel在XPU方向上探索不同架構運算的方向之一。
(2)微型化矽光:這個技術方向可能在層級上更偏高了一些,不再晶片架構層級,不過仍然值得一提。去年Intel在Labs Day上特別談到了自己在矽光(Silicon Photonics)的一些技術進展。其實矽光技術在連接資料中心的交換機方面,已有應用了,發出資料時,連接埠處會有個收發器把電訊號轉為光訊號,透過光纖來傳輸資料,另一端光訊號再轉為電訊號。不過傳統的光收發器成本都比較高,內部元件數量大,尺寸也就比較大。
Intel在整合化的矽光(IIIV族monolithic的光學整合化方案)方面應該是商業化走在比較前列的,就是把光和電子相關的組成部分高度整合到晶片上,用IC製造技術。未來的光通訊不只是資料中心機架到機架之間,也可以下沉到板級——就跟現在傳統的電I/O一樣。電互連的主要問題是功耗太大,也就是所謂的I/O功耗牆,這是這類微型化矽光元件存在的重要價值。
這其中存在的技術挑戰還是比較多,如做資料的光訊號調變的調變器調變器,據說Intel的技術使其實現了1,000倍的縮小;還有在接收端需要有個探測器(detector)轉換光訊號,用所謂的全矽微環(micro-ring)結構,實現矽對光的檢測能力;波分複用技術實現頻寬倍增,以及把矽光和CMOS晶片做整合等。
Intel認為,把矽光模組與運算資源整合,就能打破必須帶更多I/O接腳做更大尺寸處理器的這種趨勢。矽光能夠實現的是更低的功耗、更大的頻寬、更小的接腳數量和尺寸。在跨處理器、跨伺服器節點之間的資料互動上,這類技術還是頗具前景,Intel此前說目標是實現每根光纖1Tbps的速率,並且能效在1pJ/bit,最遠距離1km,這在非本地傳輸上是很理想的數字。
還有軟體…
除了AI晶片本身,從整個生態的角度,包括AI感知到運算的整個鏈條上的其他組成部分,都有促成性能和效率提升的餘地。比如這兩年Nvidia從軟體層面,針對AI運算的中間層、庫做了大量最佳化。相同的底層硬體,透過軟體最佳化就能實現幾倍的性能提升。
宋繼強說,「我們發現軟體最佳化與否,在同一個硬體上可以達到百倍的性能差距。」這其中的餘量還是比較大。
在AI開發生態上,雖然Nvidia是最具發言權的;但從戰略角度來看,像Intel這種研發CPU、GPU、FPGA、ASIC,甚至還有神經型態運算處理器的企業而言,不同處理器統一開發生態可能更具前瞻性。Intel有個稱oneAPI的軟體平台,用一套API實現不同硬體性能埠的對接。這類策略對廠商的軟體框架構建能力是非常大的考驗——也極大程度關乎底層晶片的執行效率。
在摩爾定律放緩、電晶體尺寸微縮變慢甚至不縮小的前提下,處理器架構革新、異質整合與2.5D/3D封裝技術依然可以達成1,000倍的性能提升;而一些新的技術方向,包括近記憶體運算、記憶體內運算和微型矽光,能夠在資料訪存、傳輸方面產生新的價值;神經型態運算這種類腦運算方式,是實現AI運算的目標;軟體層面的最佳化,也能夠帶動AI性能的成倍增長。所以即便摩爾定律嚴重放緩,AI晶片的性能、效率提升在上面提到的這麼多方案加持下,終將在未來很長一段時間內持續飛越。這第三(四)次科技革命恐怕還很難停歇。
資料來源:https://www.eettaiwan.com/20210726nt61-ai-computing/?fbclid=IwAR3BaorLm9rL2s1ff6cNkL6Z7dK8Q96XulQPzuMQ_Yky9H_EmLsBpjBOsWg
陣列定義 在 Taipei Ethereum Meetup Facebook 的最佳貼文
📜 [專欄新文章] Merkle Tree in JavaScript
✍️ Johnson
📥 歡迎投稿: https://medium.com/taipei-ethereum-meetup #徵技術分享文 #使用心得 #教學文 #medium
這篇文章會說明 Merkle Tree 的運作原理,以及解釋 Merkle Proofs 的用意,並以 JavaScript / TypeScript 簡單實作出來。
本文為 Tornado Cash 研究系列的 Part 1,本系列以 tornado-core 為教材,學習開發 ZKP 的應用,另兩篇為:
Part 2:ZKP 與智能合約的開發入門
Part 3:Tornado Cash 實例解析
Special thanks to C.C. Liang for review and enlightenment.
本文中實作的 Merkle Tree 是以 TypeScript 重寫的版本,原始版本為 tornado-core 以 JavaScript 實作而成,基本上大同小異。
Merkle Tree 的原理
在理解 Merkle Tree 之前,最基本的先備知識是 hash function,利用 hash 我們可以對資料進行雜湊,而雜湊後的值是不可逆的,假設我們要對 x 值做雜湊,就以 H(x) 來表示,更多內容可參考:
一次搞懂密碼學中的三兄弟 — Encode、Encrypt 跟 Hash
SHA256 Online
而所謂的 Merkle Tree 就是利用特定的 hash function,將一大批資料兩兩進行雜湊,最後產生一個最頂層的雜湊值 root。
當有一筆資料假設是const leaves = [A, B, C, D],我們就用function Hash(left, right),開始製作這顆樹,產生H(H(A) + H(B))與H(H(C) + H(D)),再將這兩個值再做一次 Hash 變成 H(H(H(A) + H(B)) + H(H(C) + H(D))),就會得到這批資料的唯一值,也就是 root。
本文中使用的命名如下:
root:Merkle Tree 最頂端的值,特色是只要底下的資料一有變動,root 值就會改變。
leaf:指單一個資料,如 H(A)。
levels:指樹的高度 (height),以上述 4 個資料的假設,製作出來的 levels 是 2,levels 通常會作為遞迴的次數。
leaves:指 Merkle Tree 上的所有資料,如上述例子中的 H(A), H(B), H(C), H(D)。leaves 的數量會決定樹的 levels,公式是 leaves.length == 2**levels,這段建議先想清楚!
node:指的是非 leaves 也非 root 的節點,或稱作 branch,如上述例子中的H(H(A) + H(B)) 和 H(H(C) + H(D))。
index:指某個 leaf 所在的位置,leaf = leaves[index],index 如果是偶數,leaf 一定在左邊,如果是奇數 leaf 一定在右邊。
Merkle Proofs
Merkle Proofs 的重點就是要證明資料有沒有在樹上。
如何證明?就是提供要證明的 leaf 以及其相對應的路徑 (path) ,經過計算後一旦能夠產生所需要的 root,就能證明這個 leaf 在這顆樹上。
因此這類要判斷資料有無在樹上的證明,類似的說法有:proving inclusion, proving existence, or proving membership。
這個 proof 的特點在於,我們只提供 leaf 和 path 就可以算出 root,而不需要提供所有的資料 (leaves) 去重新計算整顆 Merkle Tree。這讓我們在驗證資料有沒有在樹上時,不需要花費大量的計算時間,更棒的是,這讓我們只需要儲存 root 就好,而不需要儲存所有的資料。
在區塊鏈上,儲存資料的成本通常很高,也因此 Merkle Tree 的設計往往成為擴容上的重點。
我們知道 n 層的 Merkle Tree 可以存放 2**n 個葉子,以 Tornado Cash 的設計來說,他們設定 Merkle Tree 有 20 層,也就是一顆樹上會有 2**20 = 1048576 個葉子,而我們用一個 root 就代表了這 1048576 筆資料。
接續上段的例子,這顆 20 層的 Merkle Tree 所產生的 Proof ,其路徑 (path) 要從最底下的葉子 hash 幾次才能到達頂端的 root 呢?答案就是跟一棵樹的 levels 一樣,我們要驗證 Proof 所要遞迴的次數就會是 20 次。
在實作之前,我們先來看 MerkleTree 在 client 端是怎麼調用的,這有助於我們理解 Merkle Proofs 在做什麼。
基本上一個 proof 的場景會有兩個人:prover 與 verifier。
在給定一筆 leaves 的樹,必定產生一特定 root。prover 標示他的 leaf 在樹上的 index 等於 2,也就是 leaves[2] == 30,以此來產生一個 proof,這個 proof 的內容大致上會是這個樣子:
對 verifier 來說,他要驗證這個 proof,就是用裡面的 leaf 去一個一個與 pathElements 的值做 hash,上述就是 H('30', 40) 後得出 node,再 hash 一次 H('19786...', node) 於是就能得出這棵樹的 root。
重點來了,這麼做有什麼意義?它的巧思在於對 verifier 來說,他只需要儲存一個 root,由 prover 提交證明給他,經過計算後產生的 root 如果跟 verifier 儲存的 root 一樣,那就證明了 prover 所提供的資料確實存在於這個樹上。
而 verifier 若不透過 proof ,要驗證某個 leaf 是否存在於樹上,也可以把 leaves = [10, 20 ,leaf ,40]整筆資料拿去做 MerkleTree 的演算法跑一趟也能產生特定的 root。
但由 prover 先行計算後所提交的 proof,讓 verifier 不必儲存整批資料,也省去了大量的計算時間,即可做出某資料有無在 Merkle Tree 上的判斷。
Sparse Merkle Tree
上述能夠證明資料有無在樹上的 Merkle Proofs 是屬於標準的 Merkle Tree 的功能。但接下來我們要實作的是稍微不一樣的樹,叫做 Sparse Merkle Tree。
Sparse Merkle Tree 的特色在於除了 proving inclusion 之外,還可以 proving non-inclusion。也就是能夠證明某筆資料不在某個 index,例如 H(A) 不在 index 2 ,這是一般 Merkle Tree 沒辦法做到的。
而要做到 non-membership 的功能其實也不難,就是我們要在沒有資料的葉子裡補上 zero value,或是說 null 值。更多內容請參考:What’s a Sparse Merkle Tree。
實作細節
本節將完整的程式碼分成三個片段來解釋。
首先,這裡使用的 Hash Function 是 MiMC,主要是為了之後在 ZKP 專案上的效率考量,你可以替換成其他較常見的 hash function 例如 node.js 內建 crypto 的 sha256:
crypto.createHash("sha256").update(data.toString()).digest("hex");
這裡定義簡單的 Merkle Tree 介面有 root, proof, and insert。
首先我們必須先給定這顆樹的 levels,也就是樹的高度先決定好,樹所能容納的資料量也因此固定為 2**levels 筆資料,至於要不要有 defaultLeaves 則看創建 Merkle Tree 的 client 自行決定,如果有 defaultLeaves 的話,constructor 就會跑下方一大段計算,對 default 資料開始作 hash 去建立 Merkle Tree。
如果沒有 defaultLeaves,我們的樹也不會是空白的,因為這是顆 Sparse Merkle Tree,這裡使用 zeroValue 作為沒有填上資料的值,zeros 陣列會儲存不同 level 所應該使用的 zero value。假設我們已經填上第 0 筆與第 1 筆資料,要填上第 2 筆資料時,第 2 筆資料就要跟 zeros[0] 做 hash,第 2 筆放左邊, zero value 放右邊。
我們將所有的點不論是 leaf, node, root 都用標籤 (index) 標示,並以 key-value 的形式儲存在 storage 裡面。例如第 0 筆資料會是 0–0,第 1 筆會是 0–1,這兩個 hash 後的節點 (node) 會是 1–0。假設 levels 是 2,1–0 節點就要跟 1–1 節點做 hash,即可產出 root (2–0)。
後半部份的重點在於 proof,先把 proof 和 traverse 看懂,基本上就算是打通任督二脈了,之後有興趣再看 insert 和 update。
sibling 是指要和 current 一起 hashLeftRight 的值…也就是相鄰在兩旁的 leaf (or node)。
到這裡程式碼的部分就結束了。
最後,讓我們回到一開始 client 調用 merkleTree 的例子:
以及 proof 的內容:
前面略過了 proof 裡頭的 pathIndices,pathIndices 告訴你的是當前的 leaf (or node) 是要放在左邊,還是放在右邊,大概是這個樣子:
if (indices == 0) hash(A, B);if (indices == 1) hash(B, A);
有興趣的讀者可以實作 verify function 看看就會知道了!
原始碼
TypeScript from gist
JavaScript from tornado-core
參考
Merkle Proofs Explained
What’s a Sparse Merkle Tree?
延伸:Verkle Tree
Merkle Tree in JavaScript was originally published in Taipei Ethereum Meetup on Medium, where people are continuing the conversation by highlighting and responding to this story.
👏 歡迎轉載分享鼓掌
陣列定義 在 Analog Devices台灣亞德諾半導體股份有限公司 Facebook 的最佳貼文
ADI發表用於參考設計整合之16通道混合訊號前端數位轉換器
Analog Devices, Inc. (ADI)推出一款16通道混合訊號前端(MxFE)數位轉換器,可用於航空航太和防務應用,包括相位陣列雷達、電子戰和地面衛星通訊(SATCOM)。新型數位轉換器包含四個AD9081或四個AD9082軟體定義的直接RF採樣收發器,目的在透過提供參考RF訊號鏈、軟體架構、電源設計和應用示例代碼協助客戶加速開發。 ADI並推出一款數位轉換處理卡與之配合使用,以便執行系統級校準演算法和展示上電相位的確定性。
查看產品頁面:www.analog.com/en/design-center/evaluation-hardware-and-software/evaluation-boards-kits/Quad-MxFE.html
觀看混合訊號前端數位轉換器和數位轉換卡的相關影片請瀏覽:www.analog.com/en/education/education-library/videos/6184061669001.html.
透過線上技術支援社群EngineerZone™聯繫工程師和ADI產品專家:ez.analog.com
ADQUADMXFE1EBZ 16通道混合訊號前端數位轉換器主要特性:
16個RF接收(Rx)通道(32個數位Rx通道)
16個RF發射(Tx)通道(32個數位Tx通道)
提供MATLAB® app script的特定應用示例和GUI
靈活的時脈分配
ADQUADMXFE-CAL數位轉換卡主要特性:
提供單獨的相鄰通道回送和組合通道回送選項
透過SMA連接器提供組合Tx和Rx通道輸出
板載對數功率檢波器,具備AD5592R數位轉換功能