雖然這篇系統架構圖圖示鄉民發文沒有被收入到精華區:在系統架構圖圖示這個話題中,我們另外找到其它相關的精選爆讚文章
在 系統架構圖圖示產品中有20篇Facebook貼文,粉絲數超過3,992的網紅台灣物聯網實驗室 IOT Labs,也在其Facebook貼文中提到, 機器學習識別特徵阻絕代測 上鏈回送監理資料庫防竄改 人臉辨識加酒精鎖阻酒駕 串區塊鏈上傳比對告警 2021-05-24社團法人台灣E化資安分析管理協會元智大學多媒體安全與影像處理實驗室 本文將介紹酒精防偽人臉影像辨識系統,結合了人臉辨識、酒精鎖以及區塊鏈應用,以解決酒駕問題,並透過監控系統避免...
同時也有2部Youtube影片,追蹤數超過1萬的網紅鍾日欣,也在其Youtube影片中提到,我是JC老師 電腦相關課程授課超過6000小時的一位AutoCAD課程講師 由於實在太多同學向JC老師反映,希望可以有線上課程學習,所以就決定錄製一系列的AutoCAD線上影片教學 而且不加密、不設限、不販售,就是純分享,希望可以幫助到有需要的朋友們 如果這部AutoCAD教學影片對你有幫助的話,請...
-
系統架構圖圖示 在 鍾日欣 Youtube 的最佳貼文
2016-09-02 15:17:01我是JC老師
電腦相關課程授課超過6000小時的一位AutoCAD課程講師
由於實在太多同學向JC老師反映,希望可以有線上課程學習,所以就決定錄製一系列的AutoCAD線上影片教學
而且不加密、不設限、不販售,就是純分享,希望可以幫助到有需要的朋友們
如果這部AutoCAD教學影片對你有幫助的話,請幫我按個讚,給我點鼓勵,也多分享給需要的朋友們喔~
---------------------------------------------------------------------------------------------------------
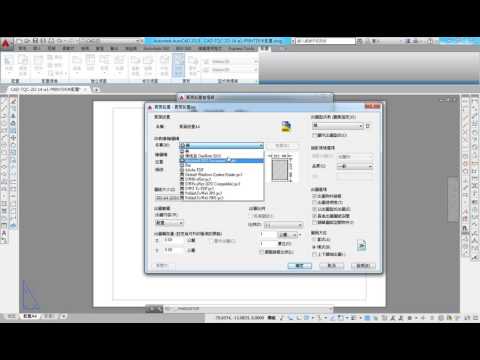
頁面設定管理員 PAGESETUP
● 配置 \ 配置 \ 頁面設定
● 控制每個新配置的頁面配置、出圖設備、圖紙大小以及其他設定。
● 頁面設置:顯示目前的頁面設置、將其他頁面設置做為目前的頁面設置、建立新頁面設置、修改既有的頁面設置、從其他圖面匯入頁面設置。
● 目前的頁面設置:顯示套用到目前配置的頁面設置。
● 「頁面設置」清單:列示可套用到目前配置或者發佈圖紙集時可用的頁面設置。將列示圖面中可用的具名頁面設置與配置。套用了具名頁面設置的配置用星號括住,該具名頁面設置用括號括住﹔例如,*Layout 1 (System Scale-to-fit)*。
● 設為目前的:將所選頁面設置設定為目前配置的目前頁面設置。您無法將目前配置設定為目前頁面設置。「設為目前的」不適用於圖紙集。
● 新建:顯示「新頁面設置」對話方塊,您可以在其中輸入新頁面設置的名稱,並指定要用來做為起點的頁面設置。
● 修改:顯示「頁面設置」對話方塊,您可以在其中編輯所選頁面設置的設定。
● 「頁面設置」對話方塊:指定頁面配置和出圖設備設定。
◆ 頁面設置
★ 名稱:顯示目前頁面設置的名稱。
◆ 印表機/繪圖機:指定當出圖或發佈配置或圖紙時要使用的規劃出圖設備。
★ 名稱:列示可用的 PC3 檔或者系統印表機,您可以從中進行選取以出圖或者發佈目前配置或圖紙。設備名稱前的圖示可標識它是 PC3 檔案還是一個系統印表機。
◆ 圖紙大小:顯示選取的出圖設備可以使用的標準圖紙大小。如果選取的繪圖機不支援這個配置的所選取圖紙大小,將顯示一則警告,並且可以選取繪圖機的預設圖紙大小或自訂圖紙大小。
◆ 出圖範圍:指定要出圖的圖面區域。
★ 配置/範圍:當出圖配置時,在指定圖紙大小的可列印區域內,每個項目都將出圖,原點從配置中的 0,0 開始算起。當從「模型」配置出圖時,將出圖由格線限制定義的整個圖面區域。如果目前的視埠不會顯示平面視圖,則這個選項和「實際範圍」選項的效果相同。
★ 實際範圍:針對圖面內目前含有物件的空間部分來予以出圖。目前配置中的所有幾何圖形均會出圖。並且可能重生此圖面,以在出圖前重新計算實際範圍。
★ 顯示:將目前配置中目前視埠中的視圖予以出圖。
★ 視圖:使用 VIEW 指令出圖先前儲存的視圖。
★ 窗選:出圖您指定的圖面的任何部分。當您指定要出圖區域的兩個角點時,「窗選」按鈕將變為可用。
◆ 出圖偏移:根據「指定出圖偏移,相對於」選項 (在「選項」對話方塊中「出圖與發佈」頁籤內) 中的設定,指定出圖範圍相對於可列印區左下角或圖紙邊的偏移。「頁面設置」對話方塊的「出圖偏移」區域顯示指定的出圖偏移選項 (用括號括住)。
★ 置中出圖:自動計算 X 偏移值與 Y 偏移值,以將出圖置於圖紙中央。
★ X:相對於「出圖偏移定義」選項的設定,指定 X 軸方向上的出圖原點。
★ Y:相對於「出圖偏移定義」選項的設定,指定 Y 軸方向上的出圖原點。
◆ 「出圖比例」:控制相對於出圖單位的圖面單位大小。如果在「出圖範圍」內指定「配置」選項,則無論在「比例」中指定的設定為何,配置均會按 1:1 出圖。
★ 單位:指定等於指定的英吋數、公釐數或像素數的單位數。
★ 調整線粗比例:依出圖比例來調整線粗比例。通常,「線粗」可指定輸出物件的線寬,並以線寬大小來輸出,而與出圖比例無關。
◆ 出圖型式表 (圖筆指定):設定出圖型式表、編輯出圖型式表,或建立新出圖型式表。
★ 名稱:顯示指定給目前「模型」頁籤或配置頁籤的出圖型式表,並提供目前可用出圖型式表的清單。
★ 顯示出圖型式:控制指定給物件的出圖型式的性質是否顯示在螢幕上。
◆ 描影視埠選項:指定描影或彩現視埠的出圖方式,並決定它們的解析度等級與每英吋的點數 (dpi)。
★ 描影出圖:
▲ 依顯示:依物件在螢幕上的顯示方式出圖物件。
▲ 線架構:無論物件在螢幕上以何種方式顯示,均以線架構方式出圖物件。
▲ 隱藏: 出圖物件時移除隱藏線。
▲ 3D 隱藏:無論物件在螢幕上以何種方式顯示,出圖物件時均套用「3D 隱藏」視覺型式。
▲ 3D 線架構:無論物件在螢幕上以何種方式顯示,出圖物件時均套用「3D 線架構」視覺型式。
▲ 概念:無論物件在螢幕上以何種方式顯示,出圖物件時均套用「概念」視覺型式。
▲ 擬真:無論物件在螢幕上以何種方式顯示,出圖物件時均套用「擬真」視覺型式。
▲ 彩現:無論物件在螢幕上以何種方式顯示,均以彩現的方式出圖物件。
★ 品質:
▲ 草圖:將彩現與描影模型空間視圖設定為以線架構方式出圖。
▲ 預覽:將彩現與描影模型空間視圖的出圖解析度設定為目前設備解析度的四分之一,且不超過 150 dpi。
▲ 正常:將彩現與描影模型空間視圖的出圖解析度設定為目前設備解析度的二分之一,且不超過 300 dpi。
▲ 簡報:將彩現與描影模型空間視圖的出圖解析度設定為目前設備解析度,且不超過 600 dpi。
▲ 最大值:將彩現與描影模型空間視圖的出圖解析度設定為目前設備解析度,且無最大值限制。
▲ 自訂:將彩現與描影模型空間視圖的出圖解析度設定為您在「DPI」方塊中指定的解析度設定,且不超過目前設備解析度。
★DPI:指定彩現或描影視圖的每英吋點數,最高可為目前出圖設備解析度的最大值。
◆ 出圖選項:指定線粗、透明度、出圖型式、描影出圖與物件出圖次序的選項。
★ 出圖物件線粗:指定是否要將指定給物件與圖層的線粗出圖。
★ 出圖透明度:指定是否出圖物件透明度。僅應在出圖具有透明度物件的圖面時使用此選項。
★ 以出圖型式出圖:指定是否要出圖套用到物件與圖層上的出圖型式。
★ 最後出圖圖紙空間:先出圖模型空間幾何圖形。通常,圖紙空間幾何圖形會在模型空間幾何圖形之前出圖。
★ 隱藏圖紙空間物件:指定 HIDE 作業是否要套用到圖紙空間視埠中的物件。此選項僅可用於配置頁籤。此設定將反映在出圖預覽中,但不會反映在配置中。
◆ 圖面方位:指定支援橫式或直式方位的繪圖機的圖紙上的圖面方位。
★ 直式:調整圖面方位並出圖圖面,使圖紙的短邊做為頁面的頂端。
★ 橫式:調整圖面方位並出圖圖面,使圖紙的長邊做為頁面的頂端。
★ 上下顛倒出圖:上下顛倒定位和出圖圖面。
---------------------------------------------------------------------------------------------------------
AutoCAD線上影片教學範例下載:https://goo.gl/DhVTau
AutoCAD2D常用快速鍵清單整理:http://goo.gl/SjNIxz
AutoCAD2015線上影片教學頻道:https://goo.gl/Q5aCf5
JC老師個人網站:http://jc-d.net/
JC老師個人FB:https://www.facebook.com/ericjc.tw![post-title]()
-
系統架構圖圖示 在 鍾日欣 Youtube 的最讚貼文
2016-09-02 13:25:07我是JC老師
電腦相關課程授課超過6000小時的一位AutoCAD課程講師
由於實在太多同學向JC老師反映,希望可以有線上課程學習,所以就決定錄製一系列的AutoCAD線上影片教學
而且不加密、不設限、不販售,就是純分享,希望可以幫助到有需要的朋友們
如果這部AutoCAD教學影片對你有幫助的話,請幫我按個讚,給我點鼓勵,也多分享給需要的朋友們喔~
---------------------------------------------------------------------------------------------------------
頁面設定管理員 PAGESETUP
● 配置 \ 配置 \ 頁面設定
● 控制每個新配置的頁面配置、出圖設備、圖紙大小以及其他設定。
● 頁面設置:顯示目前的頁面設置、將其他頁面設置做為目前的頁面設置、建立新頁面設置、修改既有的頁面設置、從其他圖面匯入頁面設置。
● 目前的頁面設置:顯示套用到目前配置的頁面設置。
● 「頁面設置」清單:列示可套用到目前配置或者發佈圖紙集時可用的頁面設置。將列示圖面中可用的具名頁面設置與配置。套用了具名頁面設置的配置用星號括住,該具名頁面設置用括號括住﹔例如,*Layout 1 (System Scale-to-fit)*。
● 設為目前的:將所選頁面設置設定為目前配置的目前頁面設置。您無法將目前配置設定為目前頁面設置。「設為目前的」不適用於圖紙集。
● 新建:顯示「新頁面設置」對話方塊,您可以在其中輸入新頁面設置的名稱,並指定要用來做為起點的頁面設置。
● 修改:顯示「頁面設置」對話方塊,您可以在其中編輯所選頁面設置的設定。
● 「頁面設置」對話方塊:指定頁面配置和出圖設備設定。
◆ 頁面設置
★ 名稱:顯示目前頁面設置的名稱。
◆ 印表機/繪圖機:指定當出圖或發佈配置或圖紙時要使用的規劃出圖設備。
★ 名稱:列示可用的 PC3 檔或者系統印表機,您可以從中進行選取以出圖或者發佈目前配置或圖紙。設備名稱前的圖示可標識它是 PC3 檔案還是一個系統印表機。
◆ 圖紙大小:顯示選取的出圖設備可以使用的標準圖紙大小。如果選取的繪圖機不支援這個配置的所選取圖紙大小,將顯示一則警告,並且可以選取繪圖機的預設圖紙大小或自訂圖紙大小。
◆ 出圖範圍:指定要出圖的圖面區域。
★ 配置/範圍:當出圖配置時,在指定圖紙大小的可列印區域內,每個項目都將出圖,原點從配置中的 0,0 開始算起。當從「模型」配置出圖時,將出圖由格線限制定義的整個圖面區域。如果目前的視埠不會顯示平面視圖,則這個選項和「實際範圍」選項的效果相同。
★ 實際範圍:針對圖面內目前含有物件的空間部分來予以出圖。目前配置中的所有幾何圖形均會出圖。並且可能重生此圖面,以在出圖前重新計算實際範圍。
★ 顯示:將目前配置中目前視埠中的視圖予以出圖。
★ 視圖:使用 VIEW 指令出圖先前儲存的視圖。
★ 窗選:出圖您指定的圖面的任何部分。當您指定要出圖區域的兩個角點時,「窗選」按鈕將變為可用。
◆ 出圖偏移:根據「指定出圖偏移,相對於」選項 (在「選項」對話方塊中「出圖與發佈」頁籤內) 中的設定,指定出圖範圍相對於可列印區左下角或圖紙邊的偏移。「頁面設置」對話方塊的「出圖偏移」區域顯示指定的出圖偏移選項 (用括號括住)。
★ 置中出圖:自動計算 X 偏移值與 Y 偏移值,以將出圖置於圖紙中央。
★ X:相對於「出圖偏移定義」選項的設定,指定 X 軸方向上的出圖原點。
★ Y:相對於「出圖偏移定義」選項的設定,指定 Y 軸方向上的出圖原點。
◆ 「出圖比例」:控制相對於出圖單位的圖面單位大小。如果在「出圖範圍」內指定「配置」選項,則無論在「比例」中指定的設定為何,配置均會按 1:1 出圖。
★ 單位:指定等於指定的英吋數、公釐數或像素數的單位數。
★ 調整線粗比例:依出圖比例來調整線粗比例。通常,「線粗」可指定輸出物件的線寬,並以線寬大小來輸出,而與出圖比例無關。
◆ 出圖型式表 (圖筆指定):設定出圖型式表、編輯出圖型式表,或建立新出圖型式表。
★ 名稱:顯示指定給目前「模型」頁籤或配置頁籤的出圖型式表,並提供目前可用出圖型式表的清單。
★ 顯示出圖型式:控制指定給物件的出圖型式的性質是否顯示在螢幕上。
◆ 描影視埠選項:指定描影或彩現視埠的出圖方式,並決定它們的解析度等級與每英吋的點數 (dpi)。
★ 描影出圖:
▲ 依顯示:依物件在螢幕上的顯示方式出圖物件。
▲ 線架構:無論物件在螢幕上以何種方式顯示,均以線架構方式出圖物件。
▲ 隱藏: 出圖物件時移除隱藏線。
▲ 3D 隱藏:無論物件在螢幕上以何種方式顯示,出圖物件時均套用「3D 隱藏」視覺型式。
▲ 3D 線架構:無論物件在螢幕上以何種方式顯示,出圖物件時均套用「3D 線架構」視覺型式。
▲ 概念:無論物件在螢幕上以何種方式顯示,出圖物件時均套用「概念」視覺型式。
▲ 擬真:無論物件在螢幕上以何種方式顯示,出圖物件時均套用「擬真」視覺型式。
▲ 彩現:無論物件在螢幕上以何種方式顯示,均以彩現的方式出圖物件。
★ 品質:
▲ 草圖:將彩現與描影模型空間視圖設定為以線架構方式出圖。
▲ 預覽:將彩現與描影模型空間視圖的出圖解析度設定為目前設備解析度的四分之一,且不超過 150 dpi。
▲ 正常:將彩現與描影模型空間視圖的出圖解析度設定為目前設備解析度的二分之一,且不超過 300 dpi。
▲ 簡報:將彩現與描影模型空間視圖的出圖解析度設定為目前設備解析度,且不超過 600 dpi。
▲ 最大值:將彩現與描影模型空間視圖的出圖解析度設定為目前設備解析度,且無最大值限制。
▲ 自訂:將彩現與描影模型空間視圖的出圖解析度設定為您在「DPI」方塊中指定的解析度設定,且不超過目前設備解析度。
★DPI:指定彩現或描影視圖的每英吋點數,最高可為目前出圖設備解析度的最大值。
◆ 出圖選項:指定線粗、透明度、出圖型式、描影出圖與物件出圖次序的選項。
★ 出圖物件線粗:指定是否要將指定給物件與圖層的線粗出圖。
★ 出圖透明度:指定是否出圖物件透明度。僅應在出圖具有透明度物件的圖面時使用此選項。
★ 以出圖型式出圖:指定是否要出圖套用到物件與圖層上的出圖型式。
★ 最後出圖圖紙空間:先出圖模型空間幾何圖形。通常,圖紙空間幾何圖形會在模型空間幾何圖形之前出圖。
★ 隱藏圖紙空間物件:指定 HIDE 作業是否要套用到圖紙空間視埠中的物件。此選項僅可用於配置頁籤。此設定將反映在出圖預覽中,但不會反映在配置中。
◆ 圖面方位:指定支援橫式或直式方位的繪圖機的圖紙上的圖面方位。
★ 直式:調整圖面方位並出圖圖面,使圖紙的短邊做為頁面的頂端。
★ 橫式:調整圖面方位並出圖圖面,使圖紙的長邊做為頁面的頂端。
★ 上下顛倒出圖:上下顛倒定位和出圖圖面。
---------------------------------------------------------------------------------------------------------
AutoCAD線上影片教學範例下載:https://goo.gl/DhVTau
AutoCAD2D常用快速鍵清單整理:http://goo.gl/SjNIxz
AutoCAD2015線上影片教學頻道:https://goo.gl/Q5aCf5
JC老師個人網站:http://jc-d.net/
JC老師個人FB:https://www.facebook.com/ericjc.tw![post-title]()

系統架構圖圖示 在 台灣物聯網實驗室 IOT Labs Facebook 的精選貼文
機器學習識別特徵阻絕代測 上鏈回送監理資料庫防竄改
人臉辨識加酒精鎖阻酒駕 串區塊鏈上傳比對告警
2021-05-24社團法人台灣E化資安分析管理協會元智大學多媒體安全與影像處理實驗室
本文將介紹酒精防偽人臉影像辨識系統,結合了人臉辨識、酒精鎖以及區塊鏈應用,以解決酒駕問題,並透過監控系統避免代測狀況發生。且利用區塊鏈不可修改的特性,將車輛與人臉資料串上區塊鏈,以確保駕駛人的不可否認性。
長長期以來「酒駕」都是一個很嚴肅且必須被重視的議題,儘管在2019年立法院修法酒駕及拒絕酒測的罰則,但是抱持僥倖心態的人還是數不勝數,導致因酒駕釀成車禍的悲劇還是一再重演,讓不少的家庭因此破滅。
據統計,從2015年到2018年的酒駕取締件數都逾10萬件,而因為酒駕車禍的死亡人數逾百人。在2019年酒駕新制上路以後,2020年警方酒駕取締件數有明顯下降至約6萬件,雖然成功達到嚇阻效果,但是死亡人數仍與去年前年持平,可見離完全遏止酒駕還有很長的路需要努力。
立法院於2018年三讀通過了「道路交通管理處罰條例部分條文修正案」,酒駕者必須重新考照,並且只能駕駛具有酒精鎖(Alcohol Interlock)的車輛,所謂酒精鎖,屬於車輛點火自動鎖定裝置,在汽車發動前必須進行酒測,通過才能將汽車發動,而且在每45分鐘至60分鐘後酒精鎖系統就會要求駕駛人在一定時間內進行重新酒測,以便防範在行車過程中有飲酒的情況發生,若駕駛人未遵守其要求,車子就會強制熄火並鎖死,必須回酒精鎖服務中心才能將鎖解開。
由於法案的方式無法完全遏止酒駕,因此許多創新科技或是企業致力於研究相關科技來解決酒駕的問題。
其中本田(Honda)汽車與日立(Hitachi)公司研發出手持型酒精含量檢測裝置,讓駕駛人必須在駕駛之前都先進行酒測,若酒精濃度超標就會將汽車載具上鎖,藉此避免酒駕意外或事故發生,且該技術結合了智慧鑰匙功能,若偵測到酒測值超標,車輛中的顯示面板將會發出警告訊號告知駕駛人,避免酒駕上路之問題。
另一方面則是解決酒精殘值之問題,因為有許多駕駛人都會認為,休息一下後,身體也無感到不適,即駕車出門,等到駕駛人被警方臨檢時才知道酒測未通過,因此收到罰單,甚至是吊銷駕照處罰等。
根據醫學研究指出,酒精是在人體體內由肝臟代謝,實際代謝時間必須看體質以及飲酒量而定。台灣酒駕防制社會關懷協會建議,喝酒後至少要10至20小時後再駕車比較安全。多數人無具備酒精代謝時間的觀念,導致駕駛人貿然上路,待意外發生或罰單臨頭時,已經為時已晚。
背景知識說明
本文介紹的方法為酒精鎖結合攝影鏡頭進行人臉辨識,並將人臉特徵資料與車輛資料串上區塊鏈,並利用區塊鏈不可篡改的特性,來避免駕駛人在解鎖酒精鎖時發生他人代測的問題。
由於人臉辨識技術具備防偽性、身分驗證的特性,因此將酒精鎖的技術結合人臉辨識,便可確認為駕駛本人。
何謂人臉辨識
人臉辨識技術屬於生物辨識的一種,基於人工智慧、機器學習、深度學習等技術,將大量人臉的資料輸入至電腦中做為模型訓練的素材,讓電腦透過演算法學習人類的面部特徵,藉以歸納其關聯性最後輸出人臉的特徵模型。
目前人臉辨識技術已經遍佈在日常生活之中,其應用面廣泛,最為常見的應用即為智慧型手機的解鎖、行動支付如LINE Pay、Apple Pay等,其他應用還包括行動網路銀行、網路郵局、社區大樓門禁管理系統、企業監控系統、機場出入關、智能ATM、中國天眼系統等。一般來說,人臉辨識皆具備以下幾個特性:
‧ 普遍性:屬於任何人皆擁有的特徵。
‧ 唯一性:除本人以外,其他人不具相同的特徵。
‧ 永續性:特徵不易隨著短時間有大幅的改變。
‧ 方便性:人臉辨識容易實施,設備容易取得,如相機鏡頭。
‧ 非接觸性:不須直接接觸儀器,也可以進行辨識,這部分考量到衛生問題以及辨識速度。
人臉辨識透過人臉特徵的分析比對進行身分的驗證,別於其他生物辨識如虹膜辨識、指紋辨識,無須近距離接觸,也可以精準地辨識身分,且具有同時辨識多人的能力。因應新冠肺炎疫情肆虐全球,人臉辨識技術也被用來管理人來人往的人流。人臉辨識的儀器可以搭配紅外線攝影機來測量人體體溫,在門禁進出管制系統中,利於提高管理效率,有效掌握到進出人員的身分,以及幫助衛生福利部在做疫調時更容易掌握到確診病患行經的足跡。
人臉辨識的步驟
人臉辨識的過程與步驟,包括人臉偵測、人臉校正、人臉特徵值的摘取,進行機器學習與深度學習、輸出人臉模型,從影像中先尋找目標人臉,偵測到目標後會將人臉進行預處理、灰階化、校正,並摘取特徵值,接著人臉資料交給電腦進行機器學習與深度學習運算,最後輸出已訓練好的模型。相關辨識的步驟,如圖1所示。
人臉偵測
基於Haar臉部檢測器的基本思想,對於一個一般的正臉而言,眼睛周圍的亮度較前額與臉頰暗、嘴巴比臉頰暗等其他明顯特徵。基於這樣的模式進行數千、數萬次的訓練,所訓練出的人臉模型,其訓練時間可能為幾個小時甚至幾天到幾周不等。利用已經訓練好的Haar人臉特徵模型,可以有效地在影像中偵測到人臉。
Python中的Dilb函式庫提供了訓練好的人臉模型,可以偵測出人臉的68個特徵點,包括臉的輪廓、眉毛、眼睛、鼻子、嘴巴。基於這些特徵點的資料就能夠進行人臉偵測,如圖2~4所示。圖中左上角的部分是偵測到的分數,若分數越高,代表該張影像就越可能是人臉,右側括弧中的編號代表子偵測器的編號,代表人臉的方向,其中0為正面、1為左側、2為右側。
人臉的預處理
偵測到人臉後,要針對圖片進行預處理。通常訓練的影像與攝影鏡頭拍出來的照片會有很大的不同,尤其會受到燈光、角度、表情等影響,為了改善這類問題,必須對圖片進行預處理以減少這類的問題,其中訓練的資料集也很重要:
‧ 幾何變換與裁剪:將影像中的人臉對齊與校正,將影像中不重要的部分進行裁切,並旋轉人臉,並使眼睛保持水平。
‧ 針對人臉的兩側用直方圖均衡化:可以增強影像中的對比度,可以改善過曝的影像或是曝光不足的問題,更有效地顯示與取得人臉目標的特徵點。
‧ 影像平滑化:影像在傳遞的過程中若受到通道、劣質取樣系統或是受到其他干擾導致影像變得粗糙,藉由使用圖形平滑處理,可以減少影像中的鋸齒效應和雜訊。
人臉特徵摘取
關於人臉特徵摘取,相關的技術說明如下:
‧ 歐式距離:人臉辨識是一個監督式學習,利用建立好的人臉模型,將測試資料和訓練資料進行匹配,最直觀的方式就是利用歐式距離來計算所有測試資料與訓練資料之間的距離,選擇差距最小者的影像作為辨識結果。由於人臉資料過於複雜,且需要大量的訓練集資料與測試集資料,會導致計算量過大,使辨識的速度過於緩慢,因此需要透過主成分分析法(Principal Components Analysis,PCA)來解決此問題。
‧ 主成分分析法:主成分分析法為統計學中的方法,目的是將大量且複雜的人臉資料進行降維,只保留影像中的主成分,即為影像中的關鍵像素,以在維持精確度的前提下加快辨識的速度。先將原本的二維影像資料每列資料減掉平均值,並計算協方差矩陣且取得特徵值與特徵向量,接著將訓練集與測試集的資料進行降維,讓新的像素矩陣中只保留主成分,最後則將降維後的測試資料與訓練資料做匹配,選擇距離最近者為辨識的結果。由於影像資料經過了降維的步驟,因此人臉辨識的速度將會大幅度地提升。
‧ 卷積神經網路:卷積神經網路(Convolutional Neural Network,CNN)是一種神經網路的架構,在影像辨識、人臉辨識至自駕車領域中都被廣泛運用,是深度學習(Deep Learning)中重要的一部分。主要的目的是透過濾波器對影像進行卷積、池化運算,藉此來提取圖片的特徵,並進行分類、辨識、訓練模型等作業。在人臉辨識的應用中,首先會輸入人臉的影像,再透過CNN從影像提取像素特徵並轉換成特定形式輸出,並用輸出的資料集進行訓練、辨識等等。
何謂酒精鎖
酒精鎖(圖5)是一種裝置在車輛載體中的配備,讓駕駛人必須在汽車發動前進行酒測,通過後才能將車輛發動。且每隔45分鐘至60分鐘會發出要求,讓駕駛人在時間內再次進行檢測。
根據歐盟經驗,提高罰款金額以及吊銷駕照只有在短期實施有效,只有勸阻的效果,若在執法上不夠嚴謹,被吊照者會轉變成無照駕駛,因此防止酒駕最有效的方法就是強制讓駕駛人無法上路,這就是「酒精鎖」的設計精神。
在本國2020年3月1日起酒駕新制通過後,針對酒駕犯有了更明確且更嚴厲的規定,在酒駕被吊銷駕照者重考後,一年內車輛要裝酒精鎖,未通過酒測者無法啟動,且必須上15小時的教育訓練才能重考,若酒駕累犯三次,要接受酒癮評估治療滿一年、十二次才能重考。
許多民眾對於「酒精鎖」議論紛紛,懷疑是否會發生找其他人代吹酒精鎖的疑慮,為防範此問題,酒精鎖在啟動後的五分鐘內重新進行吹氣,且汽車在行駛期間的每45至60分鐘內,便會隨機要求駕駛重新進行酒測,如果沒有通過測量或是沒有測量,整合在汽車智慧顯示面板的酒精鎖便會發出警告,並勸告駕駛停止駕車。
對於酒精鎖的實施,目前無法完全普及到每一台車子,而且對於沒有飲酒習慣的民眾而言,根本是多此一舉,反而增加不少麻煩給駕駛。若還有每45~60分鐘的隨機檢測,會導致多輛汽車必須臨時停靠路邊進行檢測,可能加劇汽車違規停車的發生頻率。
認識區塊鏈
區塊鏈技術是一種不依賴於第三方,透過分散式節點(Peer to Peer,P2P)來進行網路數據的存儲、交易與驗證的技術方法。本質上就是一個去中心化的資料庫,任何人在任何時間都可以依照相同的技術標準將訊息打包成區塊並串上區塊鏈,而這些被串上區塊鏈的區塊無法再被更改。區塊鏈技術主要依靠了密碼學與HASH來保護訊息安全,也是賦予區塊鏈技術具有高安全性、不可篡改性以及去中心化的關鍵。區塊鏈相關概念,如圖6所示。
區塊鏈的原理與特性
可以將區塊鏈想像成是一個大型公開帳本,網路上的每個節點都擁有完整的帳本備份,當產生一筆交易時,會將這筆交易廣播到各個節點,而每個節點會將未驗證的交易HASH值收集至區塊內。接著,每個節點進行工作量證明,選取計算最快的節點進行這些交易的驗證,完成後會把區塊廣播給到其他節點,其他節點會再度確認區塊中包含的交易是否有效,驗證過後才會接受區塊並串上區塊鏈,此時就無法再將資料進行篡改。
關於區塊鏈的特性,可分成以下四部分做說明:
1. 去中心化:區塊鏈其中一個最重要的核心宗旨,就是「去中心化」,區塊鏈採用分散式的點對點傳輸,該概念架構中,節點與節點之中沒有所謂的中心,所有的操作都部署在分散式的節點中,而無須部署在中心化機構的伺服器,一筆交易或資料的傳輸不再需要第三方的介入,因此又可以說每個節點就是所謂的「中心」。這樣的結構也加強了區塊鏈的穩定性,不會因為其中的部分節點故障而癱瘓整個區塊鏈的結構。
2. 不可篡改性:透過密碼學與雜湊函數的運用來將資料打包成區塊並上鏈,所有區塊都有屬於它的時間戳記,並依照時間順序排序,而所有節點的帳本資料中又記錄了完整的歷史內容,讓區塊鏈無法進行更改或是更改成本很高,因此使區塊鏈具備「不可篡改性」,並且同時確保了資料的完整性、安全性以及真實性。
3. 可追溯性:區塊鏈是一種鏈式的資料結構,鏈上的訊息區塊依照時間的順序環環相扣,這便使得區塊鏈具有可追溯的特性。可追本溯源的特性適用在廣泛的領域中,如供應鏈、版權保護、醫療、學歷認證等。區塊鏈就如同記帳帳本一般,每筆交易記錄著時間和訊息內容,若要進行資料的更改,則會視為一筆新的交易,且舊的紀錄仍會存在無法更動,因此仍可依照過去的交易事件進行追溯。
4. 匿名性:在去中心化的結構下,節點與節點之間不分主從關係,且每個節點中都擁有一本完整的帳本,因此區塊鏈系統是公開透明的。此時,個人資料與訊息內容的隱私就非常重要,區塊鏈技術運用了HASH運算、非對稱式加密與數位簽章等其他密碼學技術,讓節點資料在完全開放的情況下,也能保護隱私以及用戶的匿名性。
區塊鏈與酒精鎖
由於區塊鏈的技術具備去中心化、記錄時間以及不可篡改的特性,且更加強酒精鎖的檢測需要身分驗證的保證性。當進行酒精鎖檢測解鎖時,系統記錄駕駛人吹氣時間以及車輛的相關資訊,還有人臉特徵資料打包成區塊並串上區塊鏈。因此,在同一時間當監控系統偵測到當前駕駛人與吹氣人不同時,此時區塊鏈中所記錄的資料便能成為一個強而有力的依據,同時也能讓其他的違規或違法事件可以更容易進行追溯。
酒駕防偽人臉辨識系統介紹
為了解決酒精鎖發生駕駛人代測的問題,酒精鎖產品應導入具有身分驗證性的人臉辨識技術。酒駕防偽人臉辨識系統即為駕駛人在進行酒精鎖解鎖時,要同時進行人臉辨識,來確保駕駛人與吹氣人為同一人。
在駕駛座前方的位置會安裝攝影鏡頭,作為駕駛的監控裝置。進行酒測吹氣的人臉資料將會輸入到該系統中的資料庫儲存,並將人臉資料以及酒測的時間戳記打包成區塊串上區塊鏈,當汽車已經駛動時,攝影鏡頭將會將當前駕駛人畫面傳回系統進行人臉比對驗證。如果驗證成功,會將通過的紀錄與時間戳一同上傳至區塊鏈,若是系統偵測到駕駛人與吹氣人為不同對象,系統將發出警示要求駕駛停車並重新進行檢測,並同時將此次異常的情況進行記錄上傳到區塊鏈中。
如果駕駛持續不遵循系統指示仍持續行駛,該系統會將區塊鏈的紀錄傳送回給開罰的相關單位,並同時發出警報以告知附近用路人該車輛處於異常情況,應先行迴避。且該車輛於熄火後,酒精鎖會將車輛上鎖,必須聯絡酒精鎖廠商或酒精鎖服務中心才能解鎖。相關的系統概念流程圖,如圖7所示。
區塊鏈打包上鏈模擬
在進行酒測解鎖完畢以及進行人臉資料儲存後,會透過CNN將影像轉換輸出成128維的特徵向量作為人臉資料的測量值,接著將128個人臉特徵向量資料取出,並隨著車輛資訊一起打包到同一個區塊,然後串上區塊鏈。取出的人臉特徵資料,如圖8所示。
要打包成區塊和上鏈的內容,包括了人臉特徵資料、車牌號碼、酒測解鎖時間點等相關輔助資料,接著透過雜湊函數將相關的資料打包成區塊。以車牌號碼ABC-1234為例,圖9顯示將車輛資料和人臉資料進行區塊鏈的打包,並進行HASH運算。
將人臉資料和車輛相關資料作為一次的交易內容,並打包區塊,經過HASH後的結果如圖10所示,其中prev_hash屬性代表鏈結串列指向前一筆資料,由於這是實作模擬情境,並無上一筆資料,其中messages屬性代表內容數,一筆代表車牌資料,另一筆則為人臉資料。time屬性則代表區塊上鏈的時間點,代表車輛解鎖的時間點。
情境演練說明
話說小禛是一間企業的上班族,平時以開車為上下班的交通工具,他的汽車配置了酒駕防偽影像辨識系統,以下模擬小禛下班後準備開車的情境。
已經下班的小禛今天打算從公司開車回家,當小禛上車準備發動車子時,他必須先拿起安裝在車上的酒測器進行吹氣,並將臉對準攝影鏡頭讓系統取得小禛的人臉影像。小禛在汽車發動前的人臉影像,如圖11所示。
待攝影鏡頭偵測到小禛的人臉後,接著系統便會擷取臉上五官的68個特徵點,如圖12所示。然後,相關數據再透過CNN轉換輸出成128維的特徵向量作為人臉資料的測量值,如圖13所示。
酒精鎖通過解鎖後,車輛隨之發動,解鎖成功的時間點將會記錄成時間戳記,隨著影像與相關資料串上區塊鏈。在行駛途中,設置在駕駛座前方的鏡頭將擷取目前駕駛的人臉,以取得駕駛人的128維人臉特徵向量測量值,並且與汽車發動前所存入的人臉資料進行比對,藉以判斷目前的駕駛人與剛才的吹氣人臉是否為同一位駕駛。當驗證通過後,也會再將通過的紀錄與時間戳上傳至區塊鏈中,如此一來,區塊鏈的訊息內容便完整記載了這一次駕車的紀錄,檢測通過的示意圖如圖14所示。
系統通過辨識後,便確認了駕駛人的身分與吹氣人一致。且透過時戳的紀錄和區塊鏈的輔助,也確保了駕駛的不可否認性。若有其他違規事件發生時,區塊鏈的紀錄便成為一個強而有力的依據來進行追溯。
如此一來,便可以預防小禛喝酒卻找其他人代吹酒測器的情況發生。在駕駛的途中,如果有需要更換駕駛人,必須待車輛靜止時,從車載系統發出更換駕駛要求,再重新進行酒測以及重複上述流程,才可以更換駕駛人。如果沒有按照該流程更換駕駛,系統將視為異常情況。
結語
酒駕一直是全球性的問題,將有高機率導致重大交通事故,造成人員傷亡、家庭破碎,進而醞釀後續更多的社會問題,皆是酒駕所引發的不良效益。為了解決酒駕的問題,各個國家都有不同的酒駕標準或是法律規範,但是大部分國家的規範和制度都只有嚇阻作用卻無法完全遏止。在不同的國家防止酒駕的方式不盡相同,有的國家如新加坡,透過監禁及鞭刑來遏止酒駕犯,又或者是薩爾瓦多,當發現酒駕直接判定死刑,這樣的制度雖嚇阻力極強,但是若讓其他國家也跟進,會造成違憲或是違反人權等問題。因此,各國都在酒駕的問題方面紛紛投入研究,想要達到零酒駕的社會。
為達成此理想,本文介紹了基於區塊鏈的酒駕防偽辨識系統,利用酒精鎖搭配人臉辨識技術以及區塊鏈技術,使有飲酒的駕駛人無法發動汽車。且該系統搭載在行車電腦中,結合攝影鏡頭的監控對駕駛進行酒測防制管理,將人臉資料、酒精鎖、解鎖時間點與相關資訊打包成區塊並上鏈。基於區塊鏈技術內容的不易篡改,可加強駕駛人的不可否認性,當汽車發生異常情況時,便能利用有效且可靠的依據進行追溯。人工智慧和物聯網時代已經來臨,透過酒駕防偽辨識系統來改善酒駕問題,在未來能夠普及並結合法規,智慧汽車以及智慧科技的應用將會帶給人們更安全、更便利的社會。
附圖:圖1 人臉辨識的步驟。
圖2 人臉特徵點偵測(正臉)。
圖3 人臉特徵點偵測(左側臉)。
圖4 人臉特徵點偵測(右側臉)。
圖5 酒精鎖。 (圖片來源:https://commons.wikimedia.org/wiki/File:Guardian_Interlock_AMS2000_1.jpg with Author: Rsheram)
圖6 區塊鏈分散式節點的概念圖。
圖7 系統概念流程圖。
圖8 取出人臉128維特徵向量。
圖9 儲存車輛相關資料及人臉資料到區塊。
圖10 HASH後及打包成區塊的結果。
圖11 汽車發動前小禛的人臉影像。
圖12 小禛的人臉影像特徵點。
圖13 小禛的人臉特徵向量資料。
圖14 系統通過酒測檢測者與駕駛人為同一人。
資料來源:https://www.netadmin.com.tw/netadmin/zh-tw/technology/CC690F49163E4AAF9FD0E88A157C7B9D
系統架構圖圖示 在 台灣物聯網實驗室 IOT Labs Facebook 的最讚貼文
AI強勢來襲 物聯終端運算需求急遽增溫
2021-03-10 11:55 聯合新聞網 / CTimes零組件
【作者: 王岫晨】
物聯網正帶動人工智慧走向終端裝置,在後疫情時代,企業對物聯網 AI 的投資與布局動作頻頻。Arm 主任應用工程師張維良指出,我們可以很明顯看到四大趨勢如下:
新冠疫情加速 AI 部署
根據 Arm 於 2020 年 8 月與<<麻省理工學院科技評論洞察(MIT Technology Review)>>合作、針對來自 12 個不同產業的 301 位 C Level 的科技專業人士進行的訪談報告顯示,超過 62% 的受訪者表示,他們正在投資並使用 AI 技術。來自大型企業組織(年營收超過 5 億美元)受訪者的部署率較高,接近 80%。較小型的企業組織(營收低於 500 萬美元)的部署率則為 58%。1/3 的受訪者表示,2020 年新冠疫情的爆發加速了他們在 AI 策略上的部署。
企業組織正在提高對 AI 的投資
超過一半(57%)的受訪者看到他們的 AI 預算在過去三年內提升,且接近四分之一的人表示,他們在 2016 年到 2019 年間,年度 AI 支出最少增加一倍。其中,大型企業在 AI 支出的增加更多,73% 來自年營收超過 5 億美元的企業組織受訪者的預算都有增加,有近三分之一的受訪者預算甚至提升超過 100%。這些投資加碼反映 AI 對企業營運持續成長且普遍的影響。
超過半數企業將 AI 部署在終端裝置或邊緣運算
儘管對於已經使用 AI 的企業組織,雲端運算是他們最喜歡的基礎架構,不過在越來越需要極低延遲的數據存取,以及終端/邊緣處理能力的應用上,為了兼顧成本效益及運算效率,越來越多應用將往數據產生的來源靠近,邊緣運算或是將資源擺在更靠進存取它們的裝置的地方,相關的部署將急起直追。
對應軟硬體攻擊與保護個資/隱私的需求
AI 對幾乎所有商業與社會活動層面的衝擊持續擴大,讓企業領袖必須正視 AI 能否在負責任的規範下使用。消費者一方面對於交易與運作流程中藉助 AI 的接受度越來越高,但也期待企業能在公平的、高道德標準,並能顧及永續發展的條件下使用這項技術,特別在個資的搜集。因此在邊緣運算上,也衍生出對應軟硬體攻擊以及保護隱私等運算能力的強烈需求。
物聯網 AI 應用將聚焦於「3V」
根據 Arm 與 Strategy Analytics 合作的報告顯示,多數的物聯網應用聚焦在一些特定的領域:基本控制(開/關)、測量(狀態、溫度、流量、噪音與震動、濕度等)、資產的狀況(所在地點以及狀況如何?),以及安全性功能、自動化、預測性維護以及遠端遙控,可參考圖一。
而終端 AI 可以在三個核心領域提供價值,而它觸及的許多物聯網領域,遍及 B2B 與 B2C(企業對消費者)的應用:震動(Vibration),語音(Voice)與視覺(Vision)。
震動
包含來自多種感測器數據的處理,從加速計感測器到溫度感測器,或來自馬達的電氣訊號。它可將智能帶進 MCU 中的終端 AI 的進展,產生不同應用領域,包括溫、濕度、壓力檢測、物理檢測(如滑倒偵測)、物質偵測(如漏水、漏氣)、磁通量偵測與電場偵測等等。運用震動分析的預測性維護(PdM),在旋轉型機器密集的製造工廠裡相當常見,可以揭露鬆脫、不平衡、錯位與軸承磨損等狀況。此外,磁感測器利用磁性浮筒與一系列可以感應並與液體表面一起移動的感測器,測量液面的高低。
語音
語音啟動在智慧家庭應用中很常見,例如智慧音箱,而它也逐漸成為啟動智慧家庭裝置與智慧家電的語音中樞,如電視、遊戲主機與其它新的電器。在工業環境中,供車床、銑床與磨床等電腦數值控制(CNC)機器使用的電腦語音引擎正在興起。語音整合在車輛中也相當關鍵,因為語音有潛力成為最安全的輸入模式。OEM 代工廠商持續對車載娛樂系統中的語音辨識系統,進行大量投資。其他車用的應用包括語音輸入文字簡訊、輸入目的地、播放特定歌曲或歌曲子集,以及選擇廣播電台頻道,甚至拋錨服務與禮賓服務等。
視覺
終端 AI 提供視覺領域全新的機會,特別是與物件檢測及辨識相關。包括觀察生產線的製造瑕疵,以及找出自動販賣機需要補貨的庫存。其它實例包括農業應用,例如依據大小與品質為農產品分級。曳引機裝上機器視覺攝影機後可即時檢測出雜草、分類其種類、分析其對農穫的威脅、進而客製化除草解決方案。在工業上,包括利用熱顯影來監控互動機器零件的溫度,讓任何異常情況很快變得顯而易見。具備終端 AI 能力的裝置,可以長期檢測微細的變化,觸發排程系統,自動採取適當的行動來預防零件故障。
推動物聯網運算需求
隨著物聯網與 AI 的進展以及 5G 的推出,更多的終端智能意謂小型且成本敏感的裝置,會愈來愈有聰明、功能也愈來愈強,同時因為對雲端與網際網路的依賴較小,也將具備更高的隱私性與可靠度。因此,Arm對於MCU核心,也 透過新的設計為微處理器帶來智能,降低半導體與開發成本,同時為想要有效提升終端數位訊號處理(DSP)與機器學習能力(ML)的產品製造商,加快他們產品上市的速度。
TinyML
微型機器學習(TinyML)的崛起,已經催化嵌入式系統與機器學習結合。它捨棄在雲端上運行複雜的機器學習模型,過程包含在終端裝置內與微控制器上運行經過優化的圖型識別模型,耗電量只有數毫瓦特。受惠於 TinyML,微控制器搭配 AI 已經開始增添各種傳統上威力更強大的元件才能執行的功能。這些功能包括語音辨識(例如,自然語言處理)、影像處理(例如物件辨識與識別),以及動作(例如震動、溫度波動等)。啟用這些功能後,準確度與安全性更高,但電池的續航力卻不會打折扣,同時也考量到各種更微妙的應用。
簡化程式碼的轉移性
把AI函式庫整合進 MCU,將本地的 AI 訓練與分析能力插入程式碼中是可能的。這讓開發人員依據從感測器、麥克風與其它終端嵌入式裝置取得的訊號,導出數據的型樣,然後從中建立模型。Arm Cortex-M55 處理器與 Ethos U55 微神經處理器(microNPU),利用像 CMSIS-DSP 與 CMSIS-NN 等常見API來簡化程式碼的轉移性,讓 MCU 與共同處理器緊密耦合以加速 AI 功能。透過推論工具把 AI 功能放在低成本的 MCU 上實作,並符合嵌入式設計需求,如此一來,有 AI 功能的 MCU 就有機會在各種物聯網應用中,讓裝置的設計改觀。
附圖:圖一 : 多數的物聯網應用聚焦在一些特定的領域。
圖二 : 不同應用對於機器學習的採用比起以往更盛。圖為Arm運算方案的對應圖。
資料來源:https://udn.com/news/story/6903/5307140?fbclid=IwAR2eJEJFLD1DFifJHQNbTkWEAjQSKBk3UFlM3whrk9T69h9tNXIw3geMQ8U
系統架構圖圖示 在 台灣物聯網實驗室 IOT Labs Facebook 的最佳解答
迎接終端AI新時代:讓運算更靠近資料所在
作者 : Andrew Brown,Strategy Analytics
2021-03-03
資料/數據(data)成長的速度越來越快。據估計,人類目前每秒產出1.7Mb的資料。智慧與個人裝置如智慧型手機、平板電腦與穿戴式裝置不但快速成長,現在我們也真正目睹物聯網(IoT)的成長,未來連網的裝置數量將遠遠超越地球的人口。
這包括種類繁多的不同裝置,像是智慧感測器與致動器,它們可以監控從震動、語音到視覺等所有的東西,以及幾乎大家可以想像到的所有東西。這些裝置無所不在,從工廠所在位置到監控攝影機、智慧手錶、智慧家庭以及自主性越來越高的車輛。隨著我們企圖測量生活週遭數位世界中更多的事物,它們的數量將持續爆炸性成長。
資料爆量成長,讓許多企業把資料從內部部署運作移到雲端。儘管集中到雲端運算的性質,在成本與資源效率、彈性與便利性有它的優點,但也有一些缺點。由於運算與儲存在遠端進行,來自終端、也就是那些在網路最邊緣裝置的資料,需要從起始點經過網際網路或其他網路,來到集中式的資料中心(例如雲端),然後在這裡處理與儲存,最後再傳回給用戶。
對於一些傳統的應用,這種方式雖然還可以接受,但越來越多的使用場景就是無法承受終端與雲端之間,資訊被接力傳遞產生的延遲。我們必須即時做出決策,網路延遲要越小越好。基於這些原因,開始有人轉向終端運算;越來越多人轉而使用智慧終端,而去中心化的程度也越來越高。此外,在這些即時應用中產生的龐大資料量,意味著處理與智慧必須在本地以分散的方式進行。
與資料成長連袂而來的,是人工智慧與機器學習(ML)也朝終端移動,並且越來越朝終端本身移動。大量來自真實世界的資訊,需要用ML的方式來進行詮釋與採取行動。透過AI與ML,是以最小的延遲分析影像、動作、影片或數量龐大的資料,唯一可行且合乎成本效益的方式。運用AI與ML的演算法與應用將在邊緣運作,在未來還將會直接在終端裝置上進行。
資料正在帶動從集中化到分散化的轉變
隨著資訊科技市場逐漸發展與成熟,網路的設計以及在其運作的所有裝置,也都跟著進化。全盛時期從服務數千個小型客戶端的主機,一直到客戶端伺服器模型中使用的越來越本地化的個人電腦運算效能,基礎架構持續重組與最佳化,以便更貼近網路上的裝置以及符合運作應用的需求。這些需求包含檔案存取與資料儲存,以及資料處理的需求。
智慧型手機與其他行動裝置的爆炸性成長,加上物聯網的快速成長,促使我們需要為如何讓資產進行最佳的部署與安排進行評估。而影響這個評估的因素,包括網路的可用性、安全性、裝置的運算力,以及把資料從終端傳送到儲存設備的相關費用,近來也已轉向使用分散式的運算模型。
從邊緣到終端:AI與ML改變終端典範
在成本、資源效率、彈性與便利性等方面,雲端有它的優點,裝置數量的急遽增加(如圖2),將導致資料產出量大幅增加。這些資料大部份都相當複雜且非結構化的,這也是為何企業只會分析1%~12% 的資料的原因之一。把大量非結構化的資料送到雲端的費用相當高、容易形成瓶頸,而且從能源、頻寬與運算力角度來看,相當沒有效率。
在終端執行進階處理與分析的能力,可協助為關鍵應用降低延遲、減少對雲端的依賴,並且更好地管理物聯網產出的巨量資料。
終端AI:感測、推論與行動
在終端部署更多智慧的主要原因之一,是為了創造更大的敏捷性。終端裝置處於網路的最邊緣與資料產生的地方,可以更快與更準確地做出回應,同時免除不必要的資料傳輸、延遲與資料移動中的安全風險,可以節省費用。
處理能力與神經網路的重大進展,正協助帶動終端裝置的新能力,另一股驅動力則是對即時資訊、效率(傳送較少的資訊到雲端)、自動化與在多數情況下,對近乎即時回應的需求。這是一個三道步驟的程序:傳送資料、資料推論(例如依據機器學習辨識影像、聲音或動作),以及採取行動(如物件是披薩,冰箱的壓縮機發出正常範圍外的聲音,因此發出警告)。
感測
處理器、微控制器與感測器產生的資料量相當龐大。例如,自駕車每小時要搜集25GB的資料。智慧家庭裝置、智慧牙刷、健身追蹤器或智慧手錶持續進化,並且與以往相比,會搜集更多的資料。
它們搜集到的資料極具價值,但每次都從各個終端節點把資料推回給雲端,數量又會過多。因此必須在終端進行處理。倘若部份的作業負載能在終端本身進行,就可以大幅提升效率。
推論
終端搜集到的資料是非結構性的。當機器學習從資料擷取到關聯性時,就是在進行推論。這表示使用AI與ML工具來幫忙訓練裝置辨識物件。拜神經網路的進展之賜,機器學習工具越來越能訓練物件以高度的精準度辨識影像、聲音與動作,這對體積越來越小的裝置,極為關鍵。
例如,圖4顯示使用像ONNX、PyTorch、Caffe2、Arm NN或 Tensorflow Lite 等神經網路工具,訓練高效能的意法半導體(ST)微控制器(MCU),以轉換成最佳化的程式碼,讓MCU進行物件辨識(這個的情況辨識對象是影像、聲音或動作)。更高效能的MCU越來越常利用這些ML工具來辨識動作、音訊或影像,而且準確度相當高,而我們接下來馬上就要對此進行檢視。這些動作越來越頻繁地從邊緣,轉移到在終端運作的MCU本身。
行動
資料一旦完成感測與推論後,結果就是行動。這有可能是回饋簡單的回應(裝置是開啟或關閉),或針對應用情況進行最佳化(戴耳機的人正在移動中,因此會針對穩定度而非音質進行最佳化),或是回饋迴路(根據裝置訓練取得的機器學習,輸送帶若發出聲音,顯示它可能歪掉了)。物聯網裝置將會變得更複雜且更具智慧,因為這些能力提升後,運算力也會因此增加。在我們使用新的機器學習工具後,一些之前在雲端或終端完成的關鍵功能,將可以移到終端本身的內部進行。
終端 AI:千里之行始於足下
從智慧型手機到車輛,今日所有電子裝置的核心都是許多的處理器、微控制器與感測器。它們執行各種任務,從最簡單到最複雜,並需要各式各樣的能力。例如,應用處理器是高階處理器,它們是為行動運算、智慧型手機與伺服器設計;即時處理器是為例如硬碟控制、汽車動力傳動系統,與無線通訊的基頻控制使用的非常高效能的處理器,至於微控制器處理器的矽晶圓面積則小了許多,能源效率也高出很多,同時擁有特定的功能。
這意味著利用ML工具訓練如MCU等較不複雜元件來執行的動作,之前必須透過威力更強大的元件才能完成,但現在邊緣與雲端則是理想的場所。這將讓較小型的裝置以更低的延遲執行更多種類的功能,例如智慧手錶、健康追蹤器或健康照護監控等穿戴式裝置。
隨著更多功能在較小型的終端進行,這將可以省下資源,包括資料傳輸費用與能源費用,同時也會產生極大的環境衝擊,特別是考量到全球目前已有超過200億台連網裝置,以及超過2,500億顆MCU(根據Strategy Analytics統計數據)。
TinyML、MCU與人工智慧
根據Google的TesnsorFlow 技術主管、同時也是深度學習與TinyML領域的指標人物 Pete Warden 表示:「令人相當興奮的是,我還不知道我們將如何使用這些全新的裝置,特別是它們後面代表的科技是如此的吸引人,我無法想像那些即將出現的全新應用。」
微型機器學習(TinyML)的崛起,已經催化嵌入式系統與機器學習結合,而兩者傳統上大多是獨立運作的。TinyML 捨棄在雲端上運作複雜的機器學習模型,過程包含在終端裝置內與微控制器上運作經過最佳化的模式識別模型,耗電量只有數毫瓦。
物聯網環境中有數十億個微型裝置,可以為各個產業提供更多的洞察與效率,包括消費、醫療、汽車與工業。TinyML 獲得 Arm、Google、Qualcomm、Arduino等業者的支持,可望改變我們處理物聯網資料的方式。
受惠於TinyML,微控制器搭配AI已經開始增添各種傳統上威力更強大的元件才能執行的功能。這些功能包括語音辨識(例如自然語言處理)、影像處理(例如物件辨識與識別),以及動作(例如震動、溫度波動等)。啟用這些功能後,準確度與安全性更高,但電池的續航力卻不會打折扣,同時也考量到各種更微妙的應用。
儘管之前提到的雲端神經網路框架工具,是取用這個公用程式最常用的方法,但把AI函式庫整合進MCU,然後把本地的AI訓練與分析能力插入程式碼中也是可行的。這讓開發人員依據從感測器、麥克風與其他終端嵌入式裝置取得的訊號導出資料模式,然後從中建立模型,例如預測性維護能力。
如Arm Cortex-M55處理器與Ethos U55微神經處理器(microNPU),利用CMSIS-DSP與CMSIS-NN等常見API來簡化程式碼的轉移性,讓MCU與共同處理器緊密耦合以加速AI功能。透過推論工具在低成本的MCU上實現AI功能並符合嵌入式設計需求極為重要,原因是具有AI功能的MCU有機會在各種物聯網應用中轉變裝置的設計。
AI在較小型、低耗電與記憶體受限的裝置中可以協助的關鍵功能,我們可以把其精華歸納至我們簡稱為「3V」的三大領域:語音(Voice,如自然語言處理)、視覺(Vision,如影像處理)以及震動(Vibration,如處理來自多種感測器的資料,包括從加速計到溫度感測器,或是來自馬達的電氣訊號)。
終端智慧對「3V」至關重要
多數的物聯網應用聚焦在一些特定的領域:基本控制(開/關)、測量(狀態、溫度、流量、噪音與震動、濕度等)、資產的狀況(所在地點以及狀況如何?),以及安全性功能、自動化、預測性維護以及遠端遙控(詳見圖 6)。
Strategy Analytics的研究顯示,許多已經完成部署或將要部署的物聯網B2B應用,仍然只需要相對簡單的指令,如基本的開/關,以及對設備與環境狀態的監控。在消費性物聯網領域中,智慧音箱的語音控制AI已經出現爆炸性成長,成為智慧家庭指令的中樞,包括智慧插座、智慧照明、智慧攝影機、智慧門鈴,以及智慧恆溫器等。消費性裝置如藍牙耳機現在已經具備情境感知功能,可以依據地點與環境,在音質優先與穩定度優先之間自動切換。
如同我們檢視的結果,終端AI可以在「3V」核心領域提供價值,而它觸及的許多物聯網領域,遍及B2B與B2C的應用:
震動:包含來自多種感測器資料的處理,從加速計感測器到溫度感測器,或來自馬達的電氣訊號。
視覺:影像與影片辨識;分析與識別靜止影像或影片內物件的能力。
語音:包括自然語言處理(NLP)、瞭解人類口中說出與寫出的語言的能力,以及使用人類語言與人類交談的能力-自然語言產生(NLG)。
垂直市場中有多種可以實作AI技術的使用場景:
震動
可以用來把智慧帶進MCU中的終端AI的進展,有各式各樣的不同應用領域,對於成本與物聯網裝置與應用的效用,都會帶來衝擊。這包括我們在圖6中點出的數個關鍵物聯網應用領域,包括:
溫度監控;
壓力監控;
溼度監控;
物理動作,包括滑倒與跌倒偵測;
物質檢測(漏水、瓦斯漏氣等) ;
磁通量(如鄰近感測器與流量監控) ;
感測器融合(見圖7);
電場變化。
一如我們將在使用場景單元中檢視的,這些能力有許多可以應用在各種被普遍部署的物聯網應用中。
語音
語音是進化的產物,也是人類溝通非常有效率的方式。因此我們常常想要用語音來對機器下指令,也不令人意外;聲音檢測是持續成長的類別。語音啟動在智慧家庭應用中很常見,例如智慧音箱,而它也逐漸成為啟動智慧家庭裝置與智慧家電的語音中樞,如電視、遊戲主機與其他新的電器。
在工業環境中,供車床、銑床與磨床等電腦數值控制(CNC)機器使用的電腦語音引擎正方興未艾。iTSpeex的ATHENA4是第一批專為這些產品設計的語音啟動作業系統。這些產品往往因為安全原因,有離線語音處理的需求,因此終端 AI 語音發展在這裡也創造出有趣的機會。用戶可以指示機器執行特定的運作,並從機器手冊與工廠文件,立即取用資訊。
語音整合在車輛中也相當關鍵。OEM 代工廠商持續對車載娛樂系統中的語音辨識系統,進行大量投資。語音有潛力成為最安全的輸入模式,因為它可以讓駕駛的眼睛持續盯著道路,而雙手仍持續握著方向盤。
對於使用觸控螢幕或硬體控制器通常需要多道步驟的複雜任務,語音辨識系統特別能勝任。這些任務包括輸入文字簡訊、輸入目的地、播放特定歌曲或歌曲子集,以及選擇廣播電台頻道。其他的服務包含如拋錨服務(或bCall)與禮賓服務。
視覺
正如我們之前已經檢視過,終端 AI 提供視覺領域全新的機會,特別是與物件檢測及辨識相關。這可能包括觀察生產線的製造瑕疵,以及找出自動販賣機需要補貨的庫存。其他實例包括農業應用,例如依據大小與品質為農產品分級。
曳引機裝上機器視覺攝影機後,我們幾乎可以即時檢測出雜草。雜草冒出後,AI可以分類雜草並估算它對農產收穫的潛在威脅。這讓農民可以鎖定特定的雜草,並打造客製的除草解決方案。機器視覺然後可以檢測除草劑的效用,並找出農地中仍具抗藥性的殘餘雜草。
使用場景
預測性維護工具已經從擷取與比較震動的量測資料,進化到提出即時的資產監控。藉由連接物聯網感測器裝置與維護軟體,我們也可能做到遠端監控。
震動分析
這種類型的預測性維護在旋轉型機器密集的製造工廠裡,相當常見。震動分析可以揭露鬆脫、不平衡、錯位與軸承磨損等狀況。例如,把震動計量器接上靠近選煤廠離心泵浦內部承軸處,就可以讓工程師建立起正常震動範圍的基線。超出這個範圍的震動,可能顯示滾珠軸承出現鬆動,需要更換。
磁感測器融合
磁感測器利用磁性浮筒與一系列可以感應並與液體表面一起移動的感測器,測量液面的高低。所有的這些應用都使用一個固定面上的磁感測器,它與附近平面的磁鐵一起作動,與這個磁鐵相對應的感測器也會移動。
聲學分析(聲音)
與震動分析相似,聲測方位分析也是供潤滑技師使用,主要是專注在主動採取潤滑措施。這意味我們可以避免移動設備時產生的過度磨損,否則會為了修理造成代價高昂的停機。實際的例子可能包括測量輸送皮帶的承軸狀況。出現過度磨損時,承軸會因為潤滑不足或錯位出現故障,可能造成整個生產流程的中斷。
聲學分析(超音波)
聲音聲學分析雖然可以用來進行主動與預測性維護,超音波聲學分析卻只能用於預測性維護。它可以在超音波範圍內找出與機器摩擦及壓力相關的聲音,並使用在會發出較細微聲音的電氣設備與機器設備。我們可以說這一類型的分析與震動或油量分析相比,更可以預測即將出現的故障。目前它部署起來比其他種類的預防性維護花費較高,但終端 AI 的進展可以促成這種細微層級的聲學檢測,大幅降低部署的費用。
熱顯影
熱顯影利用紅外線影像來監控互動機器零件的溫度,讓任何異常情況很快變得顯而易見。具備終端 AI 能力的裝置,可以長期檢測微細的變化。與其他對事故敏感的監視器一樣,它們會觸發排程系統,自動採取適當的行動來預防零件故障。
消費者與智慧家庭
將語音運用在消費者與智慧家庭,是最常看到的場景之一。這包括智慧型手機與平板電腦上、未包含電話整合功能的裝置,例如螢幕尺寸有限的穿戴式裝置。這類型的裝置包含智慧手錶與健康穿戴式裝置,可以為各種功能提供免動手的語音啟動。像 Amazon 的 Echo 或 Google 的 Home 等智慧音箱市場的成長,說明消費者對於可接收與提供語音互動等現有裝置的強勁需求,與日俱增。
消費者基於各種理由使用智慧音箱,最常見的使用場景為:
聽音樂;
控制如照明等智慧家庭裝置;
取得新聞與天氣預報的更新;
建立購物與待辦事項清單。
除了像智慧音箱與智慧電視等消費裝置,智慧家庭裝置語音的使用,也顯現相當的潛力。諸如連網門鈴(如 ring.com)等裝置與連網的煙霧偵測器(例如 Nest Protect 煙霧與一氧化碳警報)目前都已上市可供消費者選購,它們結合了語音與視覺的感測器融合功能以及運動檢測。有了連網的煙霧偵測器,裝置在偵測到煙霧或一氧化碳時,可以發出語音警告。
終端 AI 為強化這些能力提供了全新機會,而且常常結合震動(動作)、視覺與語音控制。例如,增加姿態辨識來控制例如電視等家電,或是把語音控制嵌入白色家電,即是以最低成本強化功能性最直接的方式。
健康照護
用來發現醫護資訊的 AI 驅動終端裝置的應用,將為病況的治療與診斷,提供更多的價值。這種資訊可能是資料,也可能是影像、影片以及說出的話,我們可以透過 AI 進行型態與診斷分析。這些資料將引發全新、更有效的治療方法,為整個產業節省成本。受惠於終端 AI 的進展,像 Google Duplex 等語音系統的複雜性將會降低。例如門診預約等勞力密集的工作,也可以轉換成 AI 活動。利用自然語言語音來延伸 AI 的使用,也可以把 AI 用在第一線的病人診斷,然後再由醫師接手提供諮詢。
其他健康照護實例包括像 Wewalk5 等物件,這是一個供半盲與全盲人員使用的智慧拐杖。它使用感測器來檢測胸口水平以上的物件,並搭配 Google Maps 與 Amazon Alexa 等 app,方便使用者提出問題。
結論
由於連網的終端裝置數量越來越多,這個世界也越來越複雜。連接到網際網路的裝置已經超過 300 億個,而微控制器的數量也超過 2,500 億,每年還會增加約 300 億個。越來越多的程序開始進行自動化,不過,把大量資料傳送到雲端涉及的延遲以及邊緣運算的額外費用,意味著許多全新、令人興奮且引人矚目的物聯網使用場景,可能無法開花結果。
解決這些挑戰的答案,並不是為雲端資料中心持續增添運算力。降低出現在邊緣的延遲雖然會有幫助,但不會解決日益分散的世界的所有挑戰。我們需要把智能應用到基礎架構中。
儘管為終端裝置增添先進的運算能力在十年前仍不可行,TinyML 技術近來的提升,已經讓位處相當邊緣的裝置 (也就是終端本身)增添智能的機會大大改觀。在終端增加運算與人工智慧能力,可以讓我們在源頭搜集到更多更具關聯性與相關的資訊。隨著裝置與資料的數量持續攀升,在源頭掌握情境化與具關聯性的資料,具有極大的價值,並將開啟全新的使用場景與營收機會。
終端裝置的機器學習,可以促成全新的終端 AI 世界。新的應用場景正在崛起,甚至跳過傳送大量資料的需求,因而紓解資料傳輸的瓶頸與延遲,並在各種作業環境中創造全新機會。終端 AI 將為我們開啟一個充滿全新機會與應用場景的世界,其中還有很多我們現在想像不到的機會。
附圖:圖1:從集中式到分散式運算的轉變。
(資料來源:《The End of Cloud Computing》,by Peter Levine,Andreessen Horowitz)
圖2:全球上網裝置安裝量。
(資料來源:Strategy Analytics)
圖3:深度學習流程。
圖4:MCU的視覺、震動與語音。
(資料來源:意法半導體)
圖5:AI 工具集執行模型轉換,以便在MCU上執行經最佳化的神經網路推論。
(資料來源:意法半導體)
圖6:物聯網企業對企業應用的使用-目前與未來。
(資料來源:Strategy Analytics)
圖7:促成情境感知的感測器融合。
(資料來源:恩智浦半導體)
資料來源:https://www.eettaiwan.com/20210303nt31-the-dawn-of-endpoint-ai-bringing-compute-closer-to-data/?fbclid=IwAR0JTRpNsJUl-DmSNpfIcymGQpkQaUgXixEaczwDpELxGCaCeJpkTyoqUtI